2008/616/SVVRozhodnutí Rady 2008/616/SVV ze dne 23. června 2008 o provádění rozhodnutí 2008/615/SVV o posílení přeshraniční spolupráce, zejména v boji proti terorismu a přeshraniční trestné činnosti
| Publikováno: | Úř. věst. L 210, 6.8.2008, s. 12-72 | Druh předpisu: | Rozhodnutí |
| Přijato: | 23. června 2008 | Autor předpisu: | Rada Evropské unie |
| Platnost od: | 26. srpna 2008 | Nabývá účinnosti: | 26. srpna 2008 |
| Platnost předpisu: | Ano | Pozbývá platnosti: | |
Text předpisu s celou hlavičkou je dostupný pouze pro registrované uživatele.
ROZHODNUTÍ RADY 2008/616/SVV
ze dne 23. června 2008
o provádění rozhodnutí 2008/615/SVV o posílení přeshraniční spolupráce, zejména v boji proti terorismu a přeshraniční trestné činnosti
RADA EVROPSKÉ UNIE,
s ohledem na článek 33 rozhodnutí Rady 2008/615/SVV (1),
s ohledem na podnět Spolkové republiky Německo,
s ohledem na stanovisko Evropského parlamentu (2),
vzhledem k těmto důvodům:
|
(1) |
Dne 23. června 2008 Rada přijala rozhodnutí 2008/615/SVV o posílení přeshraniční spolupráce, zejména v boji proti terorismu a přeshraniční trestné činnosti. |
|
(2) |
Rozhodnutím 2008/615/SVV byly do právního rámce Evropské unie převzaty základní prvky Smlouvy ze dne 27. května 2005 mezi Belgickým královstvím, Spolkovou republikou Německo, Španělským královstvím, Francouzskou republikou, Lucemburským velkovévodstvím, Nizozemským královstvím a Rakouskou republikou o posílení přeshraniční spolupráce, zejména v boji proti terorismu, přeshraniční trestné činnosti a nedovolené migraci (dále jen „Prümská smlouva“). |
|
(3) |
Článek 33 rozhodnutí 2008/615/SVV stanoví, že Rada přijímá opatření nezbytná k provedení rozhodnutí 2008/615/SVV na úrovni Unie postupem podle čl. 34 odst. 2 písm. c) druhé věty Smlouvy o Evropské unii. Tato opatření mají vycházet z prováděcí dohody ze dne 5. prosince 2006 o administrativním a technickém provádění Prümské smlouvy. |
|
(4) |
Tímto rozhodnutím se stanoví společné předpisy, které jsou nezbytné pro administrativní a technické provádění rozhodnutí 2008/615/SVV. Příloha tohoto rozhodnutí obsahuje prováděcí předpisy technické povahy. Generální sekretariát Rady dále vypracuje a bude aktualizovat samostatnou příručku obsahující výlučně věcné informace poskytované členskými státy. |
|
(5) |
S ohledem na technické možnosti se běžné vyhledávání nových profilů DNA bude v zásadě provádět prostřednictvím jednotlivých vyhledávání a na technické úrovni se naleznou vhodná řešení, |
ROZHODLA TAKTO:
KAPITOLA I
OBECNÁ USTANOVENÍ
Článek 1
Cíl
Tímto rozhodnutím se stanoví nezbytné administrativní a technické předpisy pro provádění rozhodnutí 2008/615/SVV, zejména pokud jde o automatizovanou výměnu údajů o DNA, daktyloskopických údajů a údajů o registraci vozidel podle kapitoly 2 uvedeného rozhodnutí, jakož i o další formy spolupráce podle kapitoly 5 uvedeného rozhodnutí.
Článek 2
Definice
Pro účely tohoto rozhodnutí se rozumí:
|
a) |
„vyhledáváním“ a „srovnáváním“ uvedeným v článcích 3, 4 a 9 rozhodnutí 2008/615/SVV postupy, kterými se určuje, zda existuje shoda údajů o DNA nebo daktyloskopických údajů, které byly sděleny jedním členským státem, a údajů o DNA nebo daktyloskopických údajů uložených v databázích jednoho, několika nebo všech členských států. |
|
b) |
„automatizovaným vyhledáváním“ uvedeným v článku 12 rozhodnutí 2008/615/SVV on-line přístup za účelem nahlédnutí do databází jednoho, několika nebo všech členských států; |
|
c) |
„profilem DNA“ písmenný nebo číselný kód, který představuje soubor identifikačních znaků nekódující části analyzovaného vzorku lidské DNA, tj. konkrétní molekulární struktury na různých místech DNA (loci); |
|
d) |
„nekódující částí DNA“ oblasti chromozomu, které nejsou geneticky vyjádřeny, tj. není známo, že by určovaly jakékoliv funkční vlastnosti organismu; |
|
e) |
„referenčními údaji o DNA“ profil DNA a referenční číslo; |
|
f) |
„referenčním profilem DNA“ profil DNA identifikované osoby; |
|
g) |
„neidentifikovaným profilem DNA“ profil DNA získaný ze stop získaných při vyšetřování trestných činů a patřících dosud neidentifikované osobě; |
|
h) |
„poznámkou“ označení profilu DNA, které provede ve své vnitrostátní databázi členský stát s uvedením, že k tomuto profilu DNA již byla při vyhledávání nebo srovnávání jiným členským státem nalezena shoda; |
|
i) |
„daktyloskopickými údaji“ zobrazení otisků prstů, zobrazení latentních otisků prstů, otisků dlaní, latentních otisků dlaní, jakož i vzory těchto zobrazení (kódované markanty), pokud jsou uloženy a zpracovávány v automatizované databázi; |
|
j) |
„údaji o registraci vozidel“ soubor údajů vymezený v kapitole 3 přílohy tohoto rozhodnutí; |
|
k) |
„jednotlivým případem“, uvedeným v čl. 3 odst. 1 druhé větě, čl. 9 odst. 1 druhé větě a čl. 12 odst. 1 druhé větě rozhodnutí 2008/615/SVV, jeden samostatný spis týkající se vyšetřování nebo trestního stíhání. Pokud tento spis obsahuje více než jeden profil DNA či více než jedny daktyloskopické údaje nebo údaje o registraci vozidel, mohou být tyto informace předány společně v rámci jednoho dotazu pro vyhledávání. |
KAPITOLA 2
SPOLEČNÁ USTANOVENÍ PRO VÝMĚNU ÚDAJŮ
Článek 3
Technické specifikace
Členské státy dodržují příslušné společné technické specifikace v souvislosti se všemi dotazy a odpověďmi spojenými s vyhledáváním a srovnáváním profilů DNA, daktyloskopických údajů a údajů o registraci vozidel. Tyto technické specifikace jsou stanoveny v příloze tohoto rozhodnutí.
Článek 4
Komunikační síť
Elektronická výměna údajů o DNA, daktyloskopických údajů a údajů o registraci vozidel mezi členskými státy probíhá prostřednictvím komunikační sítě transevropských služeb pro telematiku mezi správními orgány (TESTA II) a jejích složek vyvinutých v budoucnu.
Článek 5
Dostupnost automatizované výměny údajů
Členské státy přijmou veškerá nezbytná opatření k zajištění toho, aby automatizované vyhledávání nebo srovnávání údajů o DNA, daktyloskopických údajů a údajů o registraci vozidel bylo možné 24 hodin denně sedm dní v týdnu. V případě technické závady se národní kontaktní místa členských států neprodleně navzájem informují a dohodnou se na přechodných alternativních postupech výměny informací v souladu s platnými právními předpisy. Automatizovaná výměna údajů se obnoví co nejdříve.
Článek 6
Referenční čísla pro údaje o DNA a daktyloskopické údaje
Referenční čísla uvedená v článku 2 a článku 8 rozhodnutí 2008/615/SVV jsou složena z kombinace:
|
a) |
kódu umožňujícího členskému státu v případě shody vyhledat osobní údaje a další informace ve svých databázích za účelem jejich poskytnutí jednomu, několika nebo všem členským státům v souladu s článkem 5 nebo 10 rozhodnutí 2008/615/SVV; |
|
b) |
kódu pro označení země původu profilu DNA nebo daktyloskopických údajů a |
|
c) |
kódu pro označení typu profilu DNA, pokud jde o údaje o DNA. |
KAPITOLA 3
ÚDAJE O DNA
Článek 7
Zásady výměny údajů o DNA
1. Členské státy používají stávající normy pro výměnu údajů o DNA, jakými jsou evropský referenční soubor (European Standard Set – ESS) nebo referenční soubor míst DNA (loci) používaný Interpolem (Interpol Standard Set of Loci – ISSOL).
2. Předávání v případě automatizovaného vyhledávání a automatizovaného srovnávání profilů DNA probíhá v rámci decentralizované struktury.
3. Přijmou se vhodná opatření na zajištění důvěrnosti a integrity údajů zasílaných do jiných členských států, včetně jejich šifrování.
4. Členské státy přijmou nezbytná opatření k zajištění integrity profilů DNA zpřístupňovaných nebo zasílaných ke srovnání ostatním členským státům. Tato opatření musí být v souladu s mezinárodními normami, jako například ISO 17025.
5. Členské státy použijí kódy členských států podle normy ISO 3166-1 alpha-2.
Článek 8
Pravidla pro dotazy a odpovědi, pokud jde o údaje o DNA
1. Žádost o automatizované vyhledávání nebo srovnávání uvedená v článcích 3 či 4 rozhodnutí 2008/615/SVV obsahuje pouze tyto informace:
|
a) |
kód členského státu přidělený žádajícímu členskému státu; |
|
b) |
datum, čas a číselné označení dotazu; |
|
c) |
profily DNA a jejich referenční čísla; |
|
d) |
typy předávaných profilů DNA (neidentifikované profily DNA nebo referenční profily DNA) a |
|
e) |
informace požadované pro řízení databázových systémů a kontrolu kvality postupů automatizovaného vyhledávání. |
2. Odpověď (srovnávací zpráva) na dotaz uvedený v odstavci 1 obsahuje pouze tyto informace:
|
a) |
údaj, zda byla nalezena jedna nebo více shod (hits) či žádná shoda (no hits); |
|
b) |
datum, čas a číselné označení dotazu; |
|
c) |
datum, čas a číselné označení odpovědi; |
|
d) |
kód členského státu přidělený žádajícímu a dožádanému členskému státu; |
|
e) |
referenční číslo žádajícího a dožádaného členského státu; |
|
f) |
typ předávaných profilů DNA (neidentifikované profily DNA nebo referenční profily DNA); |
|
g) |
požadované a shodující se profily DNA a |
|
h) |
informace požadované pro řízení databázových systémů a kontroly kvality postupů automatizovaného vyhledávání. |
3. Automatizované oznámení o shodě je vydáno pouze v případě, kdy automatizované vyhledávání nebo srovnávání nalezlo shodu minimálního počtu míst DNA (loci). Tento minimální počet je stanoven v kapitole 1 přílohy tohoto rozhodnutí.
4. Členské státy zajistí, aby žádosti byly v souladu s prohlášeními vydanými podle čl. 2 odst. 3 rozhodnutí 2008/615/SVV. Tato prohlášení se znovu uvedou v příručce uvedené v čl. 18 odst. 2 tohoto rozhodnutí.
Článek 9
Předávání neidentifikovaných profilů DNA za účelem automatizovaného vyhledávání podle článku 3 rozhodnutí 2008/615/SVV
1. Pokud nebyla při vyhledávání pomocí neidentifikovaného profilu DNA ve vnitrostátní databázi nalezena žádná shoda nebo byla nalezena shoda s neidentifikovaným profilem DNA, může být tento neidentifikovaný profil DNA posléze předán databázím všech dalších členských států, a pokud se při vyhledávání v databázích jiných členských států pomocí tohoto neidentifikovaného profilu DNA shody v referenčních profilech DNA nebo neidentifikovaných profilech DNA naleznou, předají se automaticky informace o těchto shodách a referenční údaje týkající se DNA žádajícímu členskému státu; pokud se v databázích jiných členských států nenaleznou žádné shody, sdělí se tato informace automaticky žádajícímu členskému státu.
2. Pokud je při vyhledávání pomocí neidentifikovaného profilu DNA v databázích jiných členských států nalezena shoda, může každý příslušný členský stát vložit do své vnitrostátní databáze za tímto účelem poznámku.
Článek 10
Předávání referenčních profilů DNA za účelem automatizovaného vyhledávání podle článku 3 rozhodnutí 2008/615/SVV
Pokud nebyla při vyhledávání pomocí referenčního profilu DNA ve vnitrostátní databázi nalezena žádná shoda s referenčním profilem DNA nebo byla nalezena shoda s neidentifikovaným profilem DNA, může být tento referenční profil DNA předán databázím všech dalších členských států, a pokud jsou při vyhledávání pomocí tohoto referenčního profilu DNA v databázích jiných členských států nalezeny shody s referenčními profily DNA nebo neidentifikovanými profily DNA, předají se automaticky informace o těchto shodách a referenční údaje o DNA žádajícímu členskému státu; pokud se v databázích jiných členských států nenaleznou žádné shody, sdělí se tato informace automaticky žádajícímu členskému státu.
Článek 11
Předávání neidentifikovaných profilů DNA za účelem automatizovaného srovnávání podle článku 4 rozhodnutí 2008/615/SVV
1. Pokud jsou při srovnávání pomocí neidentifikovaných profilů DNA v databázích jiných členských států nalezeny shody s referenčními profily DNA nebo neidentifikovanými profily DNA, předají se automaticky informace o těchto shodách a referenční údaje o DNA žádajícímu členskému státu.
2. Pokud jsou při srovnávání pomocí neidentifikovaných profilů DNA v databázích jiných členských států nalezeny shody s neidentifikovanými profily DNA nebo referenčními profily DNA, může každý příslušný členský stát do své vnitrostátní databáze vložit za tímto účelem poznámku.
KAPITOLA 4
DAKTYLOSKOPICKÉ ÚDAJE
Článek 12
Zásady pro výměnu daktyloskopických údajů
1. Digitalizace daktyloskopických údajů a jejich přenos ostatním členským státům se provádí podle jednotného datového formátu vymezeného v kapitole 2 přílohy tohoto rozhodnutí.
2. Každý členský stát zajistí, aby daktyloskopické údaje, které předává, měly dostatečnou kvalitu pro srovnávání pomocí automatizovaného systému identifikace otisků prstů (AFIS).
3. Předávání za účelem výměny daktyloskopických údajů probíhá v rámci decentralizované struktury.
4. Přijmou se vhodná opatření k zajištění důvěrnosti a integrity daktyloskopických údajů zasílaných do jiných členských států, včetně jejich šifrování.
5. Členské státy použijí kódy členských států podle normy ISO 3166-1 alpha-2.
Článek 13
Kapacity pro vyhledávání daktyloskopických údajů
1. Každý členský stát zajistí, že jeho žádosti o vyhledávání nepřekročí kapacity pro vyhledávání vymezené dožádaným členským státem. Členské státy předloží generálnímu sekretariátu Rady prohlášení uvedená v čl. 18 odst. 2, v nichž stanoví u daktyloskopických údajů o identifikovaných osobách a u daktyloskopických údajů o osobách dosud neidentifikovaných své maximální denní kapacity pro vyhledávání.
2. Maximální počet kandidátů přijatých k ověření pomocí přenosu je uveden v kapitole 2 přílohy tohoto rozhodnutí.
Článek 14
Pravidla pro žádosti a odpovědi, pokud jde o daktyloskopické údaje
1. Dožádaný členský stát neprodleně zkontroluje kvalitu předávaných daktyloskopických údajů s využitím plně automatizovaného postupu. Pokud by údaje byly pro automatizované srovnávání nevhodné, dožádaný členský stát o tom neprodleně informuje žádající členský stát.
2. Dožádaný členský stát provádí vyhledávání v pořadí, ve kterém obdržel žádosti. Žádosti jsou zpracovány s využitím plně automatizovaného postupu do 24 hodin. Žádající členský stát může, pokud tak stanoví jeho vnitrostátní právo, požádat o urychlené provedení těchto žádostí o vyhledávání a dožádaný členský stát provede tato vyhledávání neprodleně. Pokud není možné dodržet lhůty z důvodu vyšší moci, provede se srovnávání neprodleně poté, co byly překážky odstraněny.
KAPITOLA 5
ÚDAJE O REGISTRACI VOZIDEL
Článek 15
Zásady automatizovaného vyhledávání údajů o registraci vozidel
1. Pro automatizované vyhledávání údajů o registraci vozidel používají členské státy speciální verzi softwarové aplikace Evropský informační systém vozidel a řidičských oprávnění (EUCARIS), speciálně vytvořené pro účely článku 12 rozhodnutí 2008/615/SVV, a aktualizované verze této aplikace.
2. Automatizované vyhledávání údajů o registraci vozidel probíhá v rámci decentralizované struktury.
3. Informace vyměňované prostřednictvím systému EUCARIS se přenášejí v zašifrované formě.
4. Datové prvky údajů o registraci vozidel, které mají být předmětem výměny, jsou vymezeny v kapitole 3 přílohy tohoto rozhodnutí.
5. Při provádění článku 12 rozhodnutí 2008/615/SVV mohou dát členské státy přednost vyhledáváním souvisejícím s bojem proti závažné trestné činnosti.
Článek 16
Náklady
Členské státy nesou společně veškeré náklady, které vyplývají ze správy, používání a údržby softwarové aplikace EUCARIS uvedené v čl. 15 odst. 1.
KAPITOLA 6
POLICEJNÍ SPOLUPRÁCE
Článek 17
Společné hlídky a jiné společné operace
1. V souladu s kapitolou 5 rozhodnutí 2008/615/SVV, a zejména s prohlášeními předloženými podle čl. 17 odst. 4, čl. 19 odst. 2 a čl. 19 odst. 4 uvedeného rozhodnutí, určí každý členský stát jedno nebo více kontaktních míst tak, aby se jiné členské státy mohly obracet na příslušné orgány, a upřesní své postupy pro zavádění společných hlídek a jiných společných operací, své postupy pro podněty jiných členských států týkajících se těchto operací, jakož i jiná praktická hlediska, a operativní postupy vztahující se k těmto operacím.
2. Generální sekretariát Rady sestaví a pravidelně aktualizuje seznam kontaktních míst a informuje příslušné orgány o veškerých změnách tohoto seznamu.
3. Podnět k zavedení společné operace mohou podat příslušné orgány každého členského státu. Před zahájením konkrétní operace se příslušné orgány uvedené v odstavci 2 písemně nebo ústně dohodnou na podrobnostech, které mohou zahrnovat například:
|
a) |
příslušné orgány členských států zabývající se danou operací; |
|
b) |
konkrétní účel dané operace; |
|
c) |
hostitelský členský stát, v němž se daná operace koná; |
|
d) |
zeměpisnou oblast hostitelského členského státu, v níž se daná operace koná; |
|
e) |
období, jehož se daná operace týká; |
|
f) |
konkrétní pomoc, kterou poskytne vysílající členský stát nebo vysílající členské státy hostitelskému členskému státu, včetně příslušníků nebo jiných úředníků, hmotných a finančních prostředků; |
|
g) |
příslušníky účastnící se operace; |
|
h) |
příslušníka pověřeného vedením operace; |
|
i) |
pravomoci, které budou v hostitelském členském státě během operace vykonávat příslušníci a jiní úředníci vysílajícího členského státu nebo vysílajících členských států; |
|
j) |
konkrétní zbraně, střelivo a vybavení, které mohou vyslaní příslušníci v průběhu operace v souladu s rozhodnutím 2008/615/SVV používat; |
|
k) |
logistické postupy, pokud jde o dopravu, ubytování a bezpečnost; |
|
l) |
přidělení nákladů na společnou operaci, pokud se liší od nákladů uvedených v čl. 34 první větě rozhodnutí 2008/615/SVV; |
|
m) |
veškeré další možné požadované prvky. |
4. Prohlášení, postupy a určení stanovené v tomto článku se uvedou znovu v příručce uvedené v čl. 18 odst. 2.
KAPITOLA 7
ZÁVĚREČNÁ USTANOVENÍ
Článek 18
Příloha a příručka
1. Další podrobnosti týkající se technického a administrativního provádění rozhodnutí 2008/615/SVV jsou uvedeny v příloze tohoto rozhodnutí.
2. Generální sekretariát Rady připraví a bude aktualizovat příručku, jež bude zahrnovat výhradně věcné informace poskytované členskými státy prostřednictvím prohlášení vydaných na základě rozhodnutí 2008/615/SVV nebo na základě tohoto rozhodnutí, anebo prostřednictvím oznámení generálnímu sekretariátu Rady. Příručka má formu dokumentu Rady.
Článek 19
Nezávislé orgány pro ochranu údajů
Členské státy informují v souladu s čl. 18 odst. 2 tohoto rozhodnutí generální sekretariát Rady o nezávislých orgánech pro ochranu údajů nebo o justičních orgánech uvedených v čl. 30 odst. 5 rozhodnutí 2008/615/SVV.
Článek 20
Příprava rozhodnutí podle čl. 25 odst. 2 rozhodnutí 2008/615/SVV
1. Rada přijme rozhodnutí uvedené v čl. 25 odst. 2 rozhodnutí 2008/615/SVV na základě hodnotící zprávy, která vychází z dotazníku.
2. Pokud jde o automatizovanou výměnu údajů podle kapitoly 2 rozhodnutí 2008/615/SVV, vychází hodnotící zpráva také z hodnotící návštěvy a zkušebního testu, který se provede poté, co dotčený členský stát v souladu s čl. 36 odst. 2 první větou rozhodnutí 2008/615/SVV informuje generální sekretariát Rady.
3. Podrobnosti týkající se tohoto postupu jsou stanoveny v kapitole 4 přílohy tohoto rozhodnutí.
Článek 21
Hodnocení výměny údajů
1. Hodnocení administrativního, technického a finančního provádění výměny údajů podle kapitoly 2 rozhodnutí 2008/615/SVV, a zejména hodnocení používání mechanismu podle čl. 15 odst. 5, se provádí pravidelně. Hodnocení se vztahuje na ty členské státy, které v době hodnocení již rozhodnutí 2008/615/SVV uplatňují, a provádí se s ohledem na kategorie údajů, u nichž již výměna údajů mezi dotyčnými členskými státy začala. Hodnocení vychází ze zpráv dotyčných členských států.
2. Další podrobnosti daného postupu jsou stanoveny v kapitole 4 přílohy tohoto rozhodnutí.
Článek 22
Vztah k prováděcí dohodě k Prümské smlouvě
Namísto odpovídajících ustanovení obsažených v prováděcí dohodě k Prümské smlouvě platí pro členské státy vázané Prümskou smlouvou příslušná ustanovení tohoto rozhodnutí a jeho přílohy, jakmile budou zcela provedeny. Veškerá ostatní ustanovení prováděcí dohody zůstávají mezi smluvními stranami Prümské smlouvy nadále platná.
Článek 23
Provádění
Členské státy přijmou opatření nezbytná k zajištění souladu s ustanoveními tohoto rozhodnutí, a to ve lhůtách uvedených v čl. 36 odst. 1 rozhodnutí 2008/615/SVV.
Článek 24
Použitelnost
Toto rozhodnutí nabývá účinku dvacet dnů po zveřejnění v Úředním věstníku Evropské unie.
V Lucemburku dne 23. června 2008.
Za Radu
předseda
I. JARC
(1) Viz strana 1 v tomto čísle Úředního věstníku.
(2) Stanovisko ze dne 21. dubna 2008 (dosud nezveřejněné v Úředním věstníku).
PŘÍLOHA
OBSAH
|
KAPITOLA 1: |
Výměna údajů o DNA |
|
1. |
Forenzní otázky související s DNA, pravidla pro porovnávání a algoritmy |
|
1.1 |
Údaje týkající se profilů DNA |
|
1.2 |
Pravidla pro porovnávání |
|
1.3 |
Pravidla pro podávání zpráv |
|
2. |
Tabulka kódů členských států |
|
3. |
Funkční analýza |
|
3.1 |
Dostupnost systému |
|
3.2 |
Druhý krok |
|
4. |
Dokument o řízení rozhraní výměny dat o DNA |
|
4.1 |
Úvod |
|
4.2 |
Definice struktury XML |
|
5. |
Struktura aplikací, zabezpečení a přenosu |
|
5.1 |
Přehled |
|
5.2 |
Struktura vyšší úrovně |
|
5.3 |
Bezpečnostní normy a ochrana údajů |
|
5.4 |
Protokoly a normy, které by se měly používat pro šifrování |
|
5.5 |
Struktura aplikace |
|
5.6 |
Protokoly a normy, které by se měly používat pro strukturu aplikace |
|
5.7 |
Přenosové prostředí |
|
KAPITOLA 2: |
Výměna daktyloskopických údajů (dokument o řízení rozhraní) |
|
1. |
Přehled obsahu souboru |
|
2. |
Formát záznamu |
|
3. |
Logický záznam typu 1: záhlaví souboru |
|
4. |
Logický záznam typu 2: popisný text |
|
5. |
Logický záznam typu 4: zobrazení ve stupních šedi s vysokým rozlišením |
|
6. |
Logický záznam typu 9: záznam markantů |
|
7. |
Záznam typu 13 – zobrazení latentního otisku s proměnlivým rozlišením |
|
8. |
Záznam typu 15 – zobrazení otisku dlaně s proměnlivým rozlišením |
|
9. |
Dodatky ke kapitole 2 |
|
9.1 |
ASCII kódy oddělovačů |
|
9.2 |
Výpočet alfanumerického kontrolního znaku |
|
9.3 |
Znakové kódy |
|
9.4 |
Přehled operací |
|
9.5 |
Definice záznamu typu 1 |
|
9.6 |
Definice záznamu typu 2 |
|
9.7 |
Komprimační kódy pro zobrazení ve stupních šedi |
|
9.8 |
Upřesnění zprávy |
|
KAPITOLA 3: |
Výměna údajů o registraci vozidel |
|
1. |
Společný soubor údajů pro automatizované vyhledávání údajů o registraci vozidel |
|
1.1 |
Definice |
|
1.2 |
Vyhledávání vozidla, vlastníka nebo držitele |
|
2. |
Zabezpečení údajů |
|
2.1 |
Přehled |
|
2.2 |
Bezpečnostní prvky týkající se výměny zpráv |
|
2.3 |
Bezpečnostní prvky, které se netýkají výměny zpráv |
|
3. |
Technické podmínky výměny údajů |
|
3.1 |
Obecný popis aplikace EUCARIS |
|
3.2 |
Funkční a nefunkční požadavky |
|
KAPITOLA 4: |
Hodnocení |
|
1. |
Postup hodnocení podle článku 20 (příprava rozhodnutí podle čl. 25 odst. 2 rozhodnutí 2008/615/SVV) |
|
1.1 |
Dotazník |
|
1.2 |
Zkušební provoz |
|
1.3 |
Hodnotící návštěva |
|
1.4 |
Zpráva pro Radu |
|
2. |
Postup hodnocení podle článku 21 prováděcího rozhodnutí |
|
2.1 |
Statistika a zpráva |
|
2.2 |
Revize |
|
3. |
Setkání odborníků |
KAPITOLA 1: Výměna údajů o DNA
1. Forenzní otázky související s DNA, pravidla týkající se porovnávání a algoritmy
1.1 Údaje týkající se profilů DNA
Profil DNA může obsahovat 24 párů čísel, která představují alely 24 lokusů, které se rovněž používají v postupech srovnávání DNA, které používá Interpol. Názvy těchto lokusů jsou uvedeny v této tabulce:
|
VWA |
TH01 |
D21S11 |
FGA |
D8S1179 |
D3S1358 |
D18S51 |
Amelogenin |
|
TPOX |
CSF1P0 |
D13S317 |
D7S820 |
D5S818 |
D16S539 |
D2S1338 |
D19S433 |
|
Penta D |
Penta E |
FES |
F13A1 |
F13B |
SE33 |
CD4 |
GABA |
Sedm šedě označených lokusů v prvním řádku tabulky představuje jak současný evropský standardní soubor lokusů (ESS), tak standardní soubor lokusů používaný Interpolem (ISSOL).
Pravidla pro zařazení:
Profily DNA poskytnuté členskými státy pro vyhledávání a srovnávání, jakož i profily DNA rozeslané za účelem vyhledávání a srovnávání musí obsahovat alespoň 6 plně určených lokusů (1) a mohou v závislosti na dostupnosti obsahovat dodatečné lokusy nebo prázdná místa. Referenční profily DNA musí obsahovat alespoň 6 ze 7 lokusů evropského standardního souboru. Aby se zvýšila přesnost shody, jsou všechny alely, jež jsou k dispozici, uloženy v indexovaných databázích profilů DNA a jsou používány pro vyhledávání a srovnávání. Každý členský stát by měl co nejdříve v závislosti na praktických možnostech zavést každý nový evropský standardní soubor lokusů, který EU přijme.
Smíšené profily DNA nejsou přípustné a hodnoty alel každého lokusu tedy budou složeny pouze ze dvou čísel, která mohou být stejná v případě homozygozity v daném lokusu.
Se zástupnými znaky a mikrovariantami je třeba nakládat podle těchto pravidel:
|
— |
Každá nečíselná hodnota s výjimkou amelogeninu obsažená v profilu (např. „o“, „f“, „r“, „na“, „nr“ či „un“) musí být automaticky převedena pro export na zástupný znak (*) a prohledávána podle všech. |
|
— |
Číselné hodnoty „0“, „1“ nebo „99“ obsažené v profilu musí být automaticky převedeny pro export na zástupný znak (*) a prohledávány podle všech. |
|
— |
Pokud jsou pro jeden lokus poskytnuty 3 alely, bude přijata první alela a zbývající 2 alely musí být automaticky převedeny pro export na zástupný znak (*) a prohledávány podle všech. |
|
— |
Pokud jsou poskytnuty hodnoty zástupného znaku pro alelu 1 nebo 2, pak budou vyhledávány obě permutace číselné hodnoty dané pro lokus (například hodnota 12, * by mohla souhlasit s 12,14 nebo 9,12). |
|
— |
Pentanukleotidové mikrovarianty (Penta D, Penta E & CD4) budou porovnávány následovně:
|
|
— |
Tetranukleotidové mikrovarianty (zbývající část databáze lokusů představují tetranukleotidy) budou porovnávány následovně:
|
1.2 Pravidla pro porovnávání
Srovnávání dvou profilů DNA bude prováděno na základě lokusů, pro které jsou k dispozici hodnoty alel u obou DNA. Před tím než je poskytnuta informace o nalezení shody, musí se obě DNA shodovat alespoň v 6 plně určených lokusech (mimo amelogeninu).
Úplná shoda (kvalita 1) je definována jako shoda, kdy jsou stejné všechny hodnoty alel srovnávaných lokusů obsažených v obou porovnávaných profilech DNA. Přibližná shoda je definována jako shoda, kdy se porovnávané profily DNA liší v jediné ze všech porovnávaných alel (kvalita 2, 3 a 4). Přibližná shoda je přijata pouze v případě, že se alespoň 6 plně určených lokusů v obou srovnávaných profilech DNA shoduje.
Důvodem pro přibližnou shodu může být:
|
— |
lidská chyba v podobě překlepu při zadávání jednoho z profilů DNA do požadavku na vyhledání nebo do databáze DNA, |
|
— |
chyba při určení alely nebo při vyhledávání alely („allele-calling“) během genotypizace DNA. |
1.3 Pravidla pro podávání zpráv
Budou podávány zprávy o úplných shodách, přibližných shodách i o nenalezení shody.
Zpráva o shodě bude zaslána žádajícímu národnímu kontaktnímu místu a bude rovněž zpřístupněna dožádanému národnímu kontaktnímu místu (s cílem umožnit dožádanému národnímu kontaktnímu místu, aby odhadlo povahu a počet možných následných žádostí o další dostupné osobní údaje a jiné informace vztahující se k profilu DNA, u kterého byla nalezena shoda, v souladu s články 5 a 10 rozhodnutí 2008/615/SVV).
2. Tabulka číselných kódů členských států
V souladu s rozhodnutím 2008/615/SVV se pro stanovení názvů domén a jiných konfiguračních parametrů aplikací výměny údajů o DNA v rámci uzavřené sítě podle Prümské smlouvy používá kód A-2 normy ISO 3166-1.
Kódy A-2 normy ISO 3166-1 jsou tyto dvoupísmenné kódy členských států.
|
Názvy členských států |
Kód |
Názvy členských států |
Kód |
|
Belgie |
BE |
Lucembursko |
LU |
|
Bulharsko |
BG |
Maďarsko |
HU |
|
Česká republika |
CZ |
Malta |
MT |
|
Dánsko |
DK |
Nizozemsko |
NL |
|
Německo |
DE |
Rakousko |
AT |
|
Estonsko |
EE |
Polsko |
PL |
|
Řecko |
EL |
Portugalsko |
PT |
|
Španělsko |
ES |
Rumunsko |
RO |
|
Francie |
FR |
Slovensko |
SK |
|
Irsko |
IE |
Slovinsko |
SI |
|
Itálie |
IT |
Finsko |
FI |
|
Kypr |
CY |
Švédsko |
SE |
|
Lotyšsko |
LV |
Spojené království |
UK |
|
Litva |
LT |
|
|
3. Funkční analýza
3.1 Dostupnost systému
Je třeba, aby žádosti podle článku 3 rozhodnutí 2008/615/SVV přicházely do cílové databáze v chronologickém pořadí, tak jak byla každá žádost zaslána, a aby odpovědi byly odeslány tak, aby dorazily do žádajícího členského státu do 15 minut od doručení žádosti.
3.2 Druhý krok
Když členský stát obdrží zprávu o shodě, je na národním kontaktním místu tohoto členského státu, aby porovnalo hodnoty profilu zadaného v rámci dotazu a hodnoty profilu obdrženého (profilů obdržených) jako odpověď a aby potvrdil a ověřil průkazní hodnotu profilu. Národní kontaktní místa se mohou navzájem kontaktovat pro účely ověření.
Postupy právní pomoci začínají po ověření existence shody mezi dvěma profily na základě „úplné shody“ nebo „přibližné shody“ zjištěné během fáze automatizovaného vyhledávání.
4. Dokument o řízení rozhraní výměny údajů o DNA (ICD)
4.1 Úvod
4.1.1
Tato kapitola definuje požadavky na výměnu informací o profilech DNA mezi systémy databází DNA všech členských států. Pole záhlaví jsou pro výměnu údajů o DNA podle Prümské smlouvy konkrétně stanoveny, část pro údaje je založena na části pro údaje o profilu DNA ve schématu XML (Extensible Markup Language, rozšířitelný značkovací jazyk) stanoveném pro bránu pro výměnu údajů o DNA používanou Interpolem.
Údaje jsou vyměňovány pomocí protokolu SMTP (Simple Mail Transfer Protocol, jednoduchý protokol pro přenos elektronické pošty) a jiných nejmodernějších technologií prostřednictvím centrálního poštovního serveru (relay mail server), který zajišťuje poskytovatel sítě. Soubor XML je přenášen v hlavní části zprávy.
4.1.2
Tento dokument definující rozhraní definuje pouze obsah zprávy (e-mailu). Všechna témata týkající se konkrétně sítí a zpráv jsou jednotně definována v zájmu poskytnutí společného technického základu pro výměnu údajů o DNA.
To zahrnuje:
|
— |
takový formát pole předmětu ve zprávě, aby umožňoval/povoloval automatizované zpracování zpráv, |
|
— |
zda je nezbytné šifrování obsahu, a pokud ano, jakou metodu je třeba zvolit, |
|
— |
maximální délku zpráv. |
4.1.3
Zpráva XML je rozčleněna na:
|
— |
část záhlaví, která obsahuje informace o přenosu, a |
|
— |
údajovou část, která obsahuje konkrétní informace o profilu, jakož i samotný profil. |
Pro žádost i odpověď je třeba používat totéž schéma XML.
Za účelem úplného ověření neidentifikovaných profilů DNA (článek 4 rozhodnutí 2008/615/SVV) je možné zaslat skupinu profilů v jedné zprávě. Je nutné určit maximální počet profilů v jedné zprávě. Tento počet závisí na maximální povolené velikosti e-mailu a bude určen po zvolení poštovního serveru.
Příklad XML:
<?version="1.0" standalone="yes"?>
<PRUEMDNAx xmlns:msxsl="urn:schemas-microsoft-com:xslt"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<header>
(…)
</header>
<datas>
(…)
</datas>
[<datas> opakující se struktura údajů, pokud je zasláno více profilů (…) v jedné zprávě SMTP, přípustné pouze pro případy podle článku 4
</datas>]
</PRUEMDNA >
4.2 Definice struktury XML
Následující definice slouží pro příklad a lepší srozumitelnost, skutečné závazné informace jsou poskytovány souborem se schématem XML (PRUEM DNA.xsd).
4.2.1
Obsahuje tato pole:
|
Fields |
Type |
Description |
|
header |
PRUEM_header |
Occurs: 1 |
|
datas |
PRUEM_datas |
Occurs: 1... 500 |
4.2.2
|
4.2.2.1 |
Záhlaví PRUEM Toto je struktura, která popisuje záhlaví souboru XML. Obsahuje tato pole:
|
|
4.2.2.2 |
PRUEM_header dir Typ údajů obsažených ve zprávě, hodnota může být:
|
|
4.2.2.3 |
PRUEM header info Struktura pro označení členského státu a dne/času zprávy. Obsahuje tato pole:
|
4.2.3
|
4.2.3.1 |
PRUEM_datas Toto je struktura, která popisuje údajovou část souboru XML. Obsahuje tato pole:
|
|
4.2.3.2 |
PRUEM_request_type Typ údajů obsažených ve zprávě, hodnota může být:
|
|
4.2.3.3 |
PRUEM_hitquality_type
|
|
4.2.3.4 |
PRUEM_data_type Typ údajů obsažených ve zprávě, hodnota může být:
|
|
4.2.3.5 |
PRUEM_data_result Typ údajů obsažených ve zprávě, hodnota může být:
|
|
4.2.3.6 |
IPSG_DNA_profile Struktura popisující profil DNA. Obsahuje tato pole:
|
|
4.2.3.7 |
IPSG_DNA_ISSOL Struktura obsahující lokusy z ISSOL (standardní soubor lokusů používaný Interpolem). Obsahuje tato pole:
|
|
4.2.3.8 |
IPSG_DNA_additional_loci Struktura obsahující jiné lokusy. Obsahuje tato pole:
|
|
4.2.3.9 |
IPSG_DNA_locus Struktura popisující lokus. Obsahuje tato pole:
|
5. Struktura aplikací, zabezpečení a přenosu
5.1 Přehled
Při provádění aplikací pro výměnu údajů o DNA v rámci rozhodnutí 2008/615/SVV je třeba používat společnou přenosovou síť, která bude mezi členskými státy logicky uzavřená. Pro efektivnější využití této společné komunikační infrastruktury umožňující zasílat žádosti a dostávat odpovědi je používán asynchronní mechanismus pro přenášení žádostí ohledně údajů o DNA a daktyloskopických údajů v uzavřených elektronických SMTP zprávách. Pro splnění bezpečnostních požadavků bude ke zřízení skutečně bezpečného průběžného (end-to-end) tunelu v síti použit systém sMIME (Secure Multipurpose Internet Mail Extensions) jako rozšíření funkce SMTP.
Jako přenosová síť pro výměnu údajů mezi členskými státy je používána operační síť TESTA (transevropské služby pro telematiku mezi správními orgány, Trans European Services for Telematics between Administrations). Síť TESTA spadá do pravomoci Evropské komise. S ohledem na to, že databáze DNA členských států a stávající vnitrostátní přístupová místa k síti TESTA mohou být umístěny v členských státech na různých pracovištích, může být přístup k síti TESTA zřízen:
|
1) |
použitím stávajících vnitrostátních přístupových míst nebo zřízením nového vnitrostátního přístupového místa k síti TESTA, nebo |
|
2) |
zřízením zabezpečeného místního propojení z pracoviště, kde je databáze DNA umístěna a řízena příslušnou agenturou členského státu, do stávajícího vnitrostátního přístupového místa k síti TESTA. |
Protokoly a normy používané při provádění aplikací rozhodnutí 2008/615/SVV vyhovují otevřeným normám a splňují požadavky stanovené tvůrci bezpečnostních politik členských států.
5.2 Struktura vyšší úrovně
V oblasti působnosti rozhodnutí 2008/615/SVV zpřístupní každý členský stát svou databázi údajů o DNA pro výměnu nebo vyhledávání ze strany jiných členských států v souladu se standardizovaným společným datovým formátem. Struktura vychází z modelu komunikace každého s každým („any-to-any communication model“) Neexistuje centrální počítačový server ani ústřední databáze pro ukládání profilů DNA.
Obrázek 1: Topologie výměny údajů o DNA
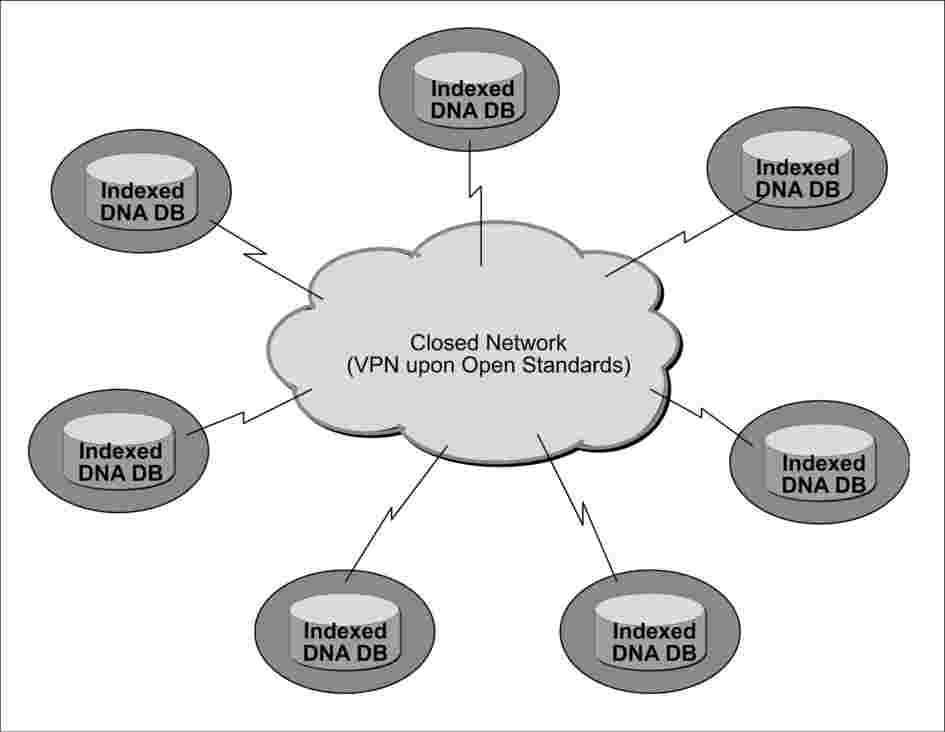
Pracoviště členských států musí respektovat vnitrostátní právní omezení a každý členský stát může kromě toho rozhodnout, jaký typ hardwaru nebo softwaru je třeba použít pro konfiguraci jeho pracoviště, aby byly splněny požadavky stanovené rozhodnutím 2008/615/SVV.
5.3 Bezpečnostní normy a ochrana údajů
Byly zváženy a provedeny tři úrovně zabezpečení.
5.3.1
Údaje o profilu DNA poskytnuté každým členským státem musí být připraveny v souladu se společnými pravidly pro ochranu údajů tak, aby žádající členské státy obdržely odpověď, která neobsahuje žádnou osobní informaci, především za účelem oznámení NALEZENÍ nebo NENALEZENÍ SHODY, v případě NALEZENÍ SHODY i s identifikačním číslem. Další šetření po oznámení o NALEZENÍ SHODY bude prováděno na bilaterální úrovni v souladu se stávajícími vnitrostátními právními a organizačními předpisy, které se vztahují na pracoviště členských států.
5.3.2
Zprávy obsahující informace o profilu DNA (v rámci žádosti a odpovědi) budou před odesláním na pracoviště jiných členských států šifrovány prostřednictvím nejmodernějších mechanismů v souladu s otevřenými normami, jako je například sMIME.
5.3.3
Všechny šifrované zprávy obsahující informace o profilu DNA budou zasílány na pracoviště jiných členských států prostřednictvím virtuálního soukromého tunelovacího systému spravovaného důvěryhodným poskytovatelem sítě na mezinárodní úrovni a zabezpečených odkazů na tento tunelovacího systému spravovaných členským státem. Tento virtuální soukromý tunelovací systém není připojen na otevřený internet.
5.4 Protokoly a normy, které by se měly používat pro šifrovací mechanismus: sMIME a související balíčky
Pro šifrování zpráv obsahujících informace o profilu DNA bude použita otevřená norma sMIME jako rozšíření existující normy pro elektronické zprávy protokolu SMTP. Protokol sMIME (V3) umožňuje podepsaná potvrzení příjmu, bezpečnostní označení, zabezpečené adresáře a je založen na syntaxi šifrované zprávy (Cryptographic Message Syntax, CMS), což je specifikace pracovní skupiny IETF (Internet Engineering Task Force) pro zprávy chráněné šifrováním. Může být používán k digitálnímu podpisu, přehledu, ověření nebo šifrování všech podob digitálních údajů.
Výchozí certifikát používaný mechanismem sMIME musí splňovat normu X.509. Aby bylo zajištěno používání společných norem a postupů při jiných aplikacích podle Prümské smlouvy, jsou pravidla pro zpracování šifrovacích operací sMIME nebo pro použití v různých prostředích COTS (Commercial Product of the Shelves) tato:
|
— |
posloupnost operací je tato: nejprve zašifrování a poté podepsání, |
|
— |
šifrovací algoritmus AES (Advanced Encryption Standard) s délkou klíče 256 bitů je používán pro symetrické šifrování a šifrovací algoritmus RSA s délkou klíče 1024 bitů je používán pro asymetrické šifrování, |
|
— |
je používán transformační algoritmus SHA-1. |
Funkce s/MIME je součástí velké většiny moderních softwarových balíčků pro elektronickou poštu, mezi něž patří Outlook, Mozilla Mail, jakož i Netscape Communicator 4.x, a funguje společně se všemi hlavními softwarovými balíčky pro elektronickou poštu.
Funkce sMIME je vzhledem ke své snadné integraci do vnitrostátní infrastruktury informačních technologií pracovišť všech členských států vybrána jakožto schůdný mechanismus pro provedení úrovně zabezpečení přenosu. Pro prototypovou výměnu údajů o DNA je však vybrána otevřená norma JavaMail API, aby bylo dosaženo cíle důkazu proveditelnosti efektivněji a s omezením nákladů. JavaMail API slouží k jednoduchému šifrování a dešifrování elektronických zpráv za pomoci s/MIME nebo OpenPGP. Záměrem je poskytnout jednotné, snadno použitelné aplikační programové rozhraní (API) pro klienty využívající elektronické pošty, kteří chtějí posílat a dostávat šifrované elektronické zprávy v obou nejoblíbenějších formátech pro šifrování elektronických zpráv. Požadavky stanovené rozhodnutím 2008/615/SVV proto dostatečně uspokojí každé nejmodernější provedení JavaMail API, jako např. produkt Bouncy Castle JCE (Java Cryptographic Extension), který bude použit pro zavedení funkce sMIME pro prototypovou výměnu údajů o DNA mezi všemi členskými státy.
5.5 Struktura aplikace
Každý členský stát poskytne ostatním členským státům soubor standardizovaných údajů o DNA, které jsou v souladu s aktuálním společným dokumentem definujícím rozhraní. Toho může být dosaženo buď poskytnutím logického pohledu do jednotlivých databází členských států, nebo zřízením skutečné exportované databáze (indexované databáze).
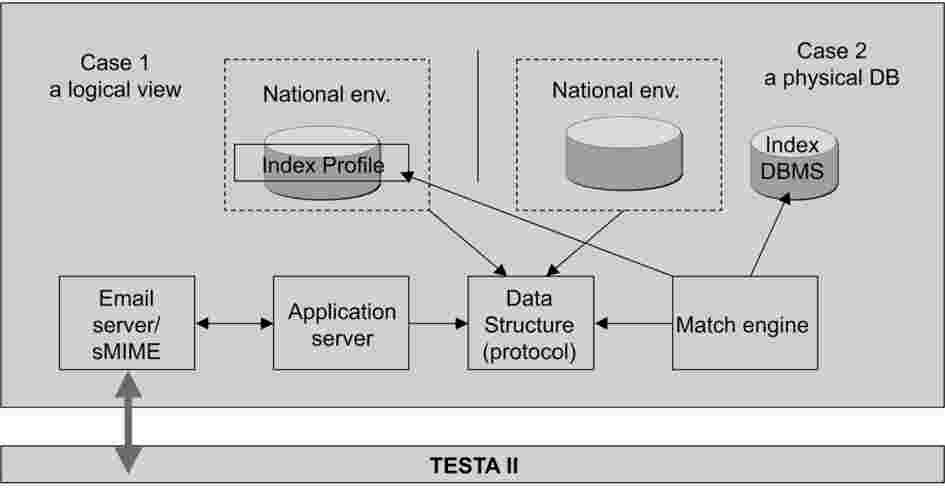
Čtyři hlavní součásti: e-mailový server/sMIME, aplikační server, oblast struktury dat („Data Structure Area“) pro vyvolání/vstup dat a registraci příchozích/odcházejících zpráv a prostředek provádějící srovnávání („Match Engine“) provádějí celou aplikační logiku nezávisle na produktu.
S cílem umožnit všem členským státům, aby tyto součásti snadno začlenily do svých pracovišť, byly zavedeny zvláštní společné funkce prostřednictvím volně šiřitelných složek, které by mohl zvolit každý členský stát v závislosti na jeho vnitrostátní politice a předpisech v oblasti informačních technologií. Díky samostatným prvkům, jež mají být zavedeny s cílem získat přístup do indexovaných databází obsahujících profily DNA, na které se vztahuje rozhodnutí 2008/615/SVV, si může každý členský stát volně vybrat vlastní hardwarovou a softwarovou platformu, včetně databází a operačních systémů.
Prototyp pro výměnu údajů o DNA byl vyvinut a úspěšně otestován na stávající společné síti. Verze 1.0 byla instalována do produktivního prostředí a je používána pro každodenní operace. Členské státy mohou používat společně vyvinutý produkt, ale mohou rovněž vyvinout své vlastní produkty. Společné součásti produktů budou udržovány, přizpůsobovány a dále rozvíjeny v souladu s měnícími se požadavky v oblasti informačních technologií, forenzní policie nebo policie jako takové.
Obrázek 2: Přehled aplikační topologie
5.6 Protokoly a normy, které by se měly používat pro strukturu aplikace
5.6.1
Výměna údajů o DNA bude plně využívat schéma XML jako přílohy k elektronickým zprávám SMTP. Rozšířitelný značkovací jazyk (eXtensible Markup Language, XML) je doporučen konsorciem W3C jako obecný značkovací jazyk pro vytváření konkrétních značkovacích jazyků, schopný popisovat mnoho různých typů dat. Popis profilu DNA vhodný pro výměnu mezi všemi členskými státy byl proveden prostřednictvím XML a schématu XML v dokumentu ICD.
5.6.2
Otevřené databázové rozhraní (Open DataBase Connectivity) je metoda standardizovaného softwarového API pro přístup k databázovým řídícím systémům a poskytuje přístup nezávislý na programovacích jazycích, databázových systémech a operačních systémech. ODBC má však určité nevýhody. Správa velkého počtu klientských zařízení může zahrnovat různé ovladače („drivers“) a knihovny DLL. Tato složitost může zvýšit náklady na správu systému.
5.6.3
Java DataBase Connectivity (JDBC) je API pro programovací jazyk Java, který definuje přístup klienta do databáze. JDBC na rozdíl od ODBC nevyžaduje použití určitého souboru lokálních knihoven DLL na daném počítači.
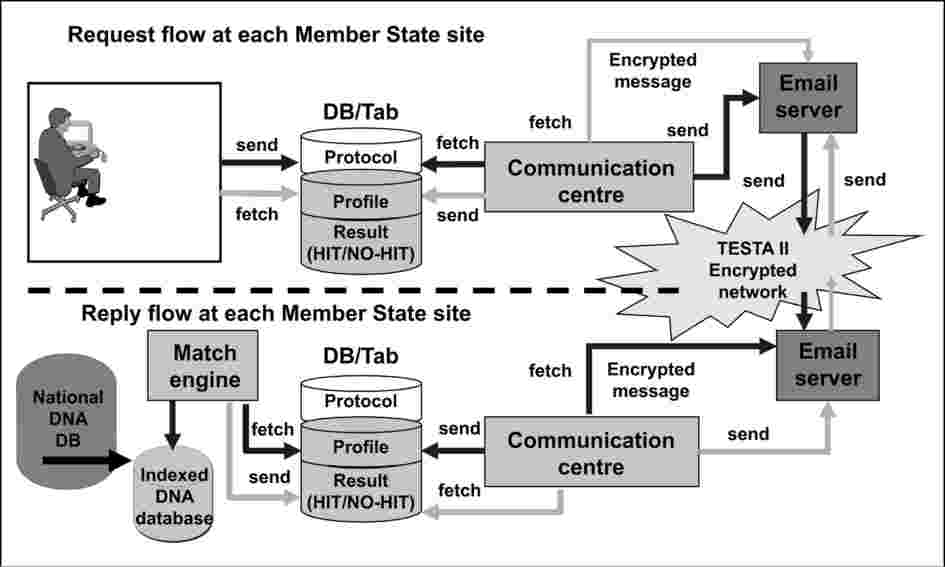
Provozní logika pro zpracování požadavků na vyhledání DNA profilů a odpovědi na pracovištích každého členského státu je znázorněna na následujícím schématu. Tok žádostí i odpovědí je propojen s neutrální oblastí údajů zahrnující různé sdružené oblasti dat se společnou strukturou dat.
Obrázek 3: Přehled aplikačního toku pracoviště každého členského státu
5.7 Přenosové prostředí
5.7.1
Aplikace pro výměnu údajů o DNA bude pro odesílání žádostí a přijímání odpovědí mezi členskými státy využívat asynchronní systém elektronické pošty. Protože všechny členské státy mají alespoň jeden vnitrostátní přístupový bod k síti TESTA, bude výměna údajů o DNA probíhat prostřednictvím sítě TESTA. TESTA poskytuje řadu služeb s přidanou hodnotou prostřednictvím e-mailového předávání zpráv. Kromě poskytování prostoru pro konkrétní e-mailové schránky sítě TESTA, tato infrastruktura může provádět politiky v oblasti adresářů pro rozesílání pošty a směrování. To umožňuje, aby síť TESTA byla používána jako referenční středisko pro zprávy určené správcům připojeným na celoevropské domény. Je rovněž možné zavést systémy pro vyhledávání virů.
E-mailové předávání zpráv prostřednictvím sítě TESTA vychází z snadno dostupné hardwarové platformy umístěné v ústředních aplikačních zařízeních a chráněné pomocí bezpečnostních bran. Služby doménových názvů sítě TESTA (TESTA Domain Name Services, DNS) převádějí zdrojové lokátory na IP adresy a skryjí adresovací prvky před uživatelem a aplikacemi.
5.7.2
V rámci sítě TESTA byla provedena koncepce virtuální soukromé sítě (Virtual Private Network, VPN). Technologie Tag Switching použitá pro vytvoření této virtuální soukromé sítě se rozvine tak, aby podporovala standard Multi-Protocol Label Switching (MPLS) vyvinutý pracovní skupinou IETF (Internet Engineering Task Force).
|
|
MPLS je standardní technologie pracovní skupiny IETF, která zvyšuje intenzitu provozu sítě, tím že ruší analýzu paketů prostřednictvím mezilehlých směrovačů (intermediate routers), (tzv. přeskoky; hops). To se děje na základě takzvaných návěští (labels), která jsou připojena k paketu prostřednictvím hraničních směrovačů (edge routers) páteřní sítě, na základě informací uložených v databázi FIB (forwarding information base). Návěští jsou rovněž používána pro provádění virtuálních soukromých sítí. |
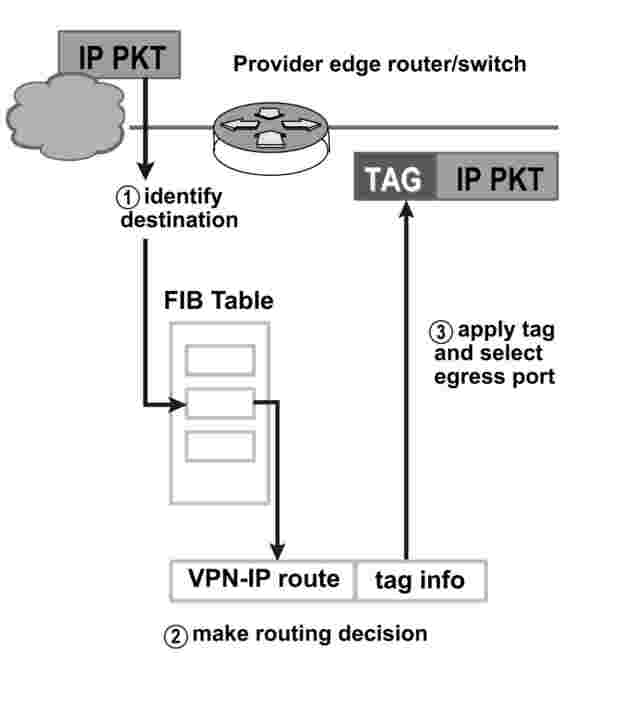
MPLS spojuje výhody směrování vrstvy 3 s výhodami přepínání vrstvy 2. Protože IP adresy nejsou během průchodu páteřní sítí vyhodnocovány, MPLS neukládá pro IP adresy žádná omezení.
Elektronické zprávy v síti TESTA budou dále chráněny prostřednictvím šifrovacího mechanismu řízeného sMIME. Bez znalosti klíče a vlastnictví správného certifikátu nebude nikdo moci zprávy na síti rozšifrovat.
5.7.3
|
5.7.3.1 |
SMTP Jednoduchý protokol pro přenos elektronické pošty (Simple Mail Transfer Protocol) je v podstatě norma pro přenos elektronických zpráv po internetu. SMTP je relativně jednoduchý, textový protokol, ve kterém jsou označeni jeden nebo více příjemců zpráv, a poté je text zprávy přenesen. SMTP používá TCP port 25 podle popisu pracovní skupiny IETF. K určení SMTP serveru pro daný doménový název je používán záznam MX (Mail eXchange) DNS (Domain Name Systems). Jelikož tento protokol začal jako čistě textový americký standardní kód pro výměnu informací (ASCII), nepracuje dobře s binárními soubory. Pro kódování binárních souborů pro přenos prostřednictvím SMTP byly vyvinuty normy jako např. MIME. V současnosti většina serverů SMTP podporuje 8BITMIME a rozšíření sMIME a umožňuje, aby byly binární soubory přenášeny téměř tak snadno jako obyčejný text. Pravidla pro zpracování pro operace sMIME jsou popsány v oddíle sMIME (viz kapitola 5.4). SMTP je „vkládací“ protokol, který neumožňuje na požádání „stahovat“ zprávy ze vzdáleného serveru. K tomu musí klient elektronické pošty použít POP3 nebo IMAP. V rámci provádění výměny údajů o DNA bylo rozhodnuto používat protokolu POP3. |
|
5.7.3.2 |
POP Lokální klienti elektronické pošty používají poštovní protokol Post Office Protocol verze 3 (POP3), aplikační standardní internetový protokol pro stahování e-mailových zpráv ze vzdáleného serveru přes TCP/IP připojení. Prostřednictvím použití profilu SMTP Submit protokolu SMTP posílají klienti elektronické pošty zprávy po internetu nebo po společné síti. MIME slouží jako standard pro přílohy a jiný text než ASCII v e-mailu. Přestože ani POP3 ani SMTP nevyžadují e-maily ve formátu MIME, internetové e-maily přicházejí v zásadě ve formátu MIME a klienti POP proto musí rovněž normě MIME rozumět a používat ji. Celé prostředí přenosu podle rozhodnutí 2008/615/SVV bude tedy zahrnovat součásti POP. |
5.7.4
Provozní prostředí
Evropský registrační orgán pro IP (RIPE) přidělil síti TESTA vyhrazený blok podsítě třídy C. V případě potřeby mohou být síti TESTA v budoucnu přiděleny další bloky adres. Přidělení IP adres členským státům vychází ze zeměpisného uspořádání v Evropě. Výměna údajů mezi členskými státy v rámci rozhodnutí 2008/615/SVV je prováděna prostřednictvím evropské logicky uzavřené sítě IP.
Testovací prostředí
Aby byl zajištěn hladký chod prostředí pro každodenní operace mezi všemi připojenými členskými státy, je nezbytné zřídit testovací prostředí na uzavřené síti pro nové členské státy, které se chystají zapojit do operací. Byl stanoven formulář s parametry obsahující IP adresy, nastavení sítě, e-mailové domény a uživatelské účty aplikací a měl by být zaveden do příslušného pracoviště členského státu. Kromě toho byl pro účely testování sestaven soubor pseudoprofilů DNA.
5.7.5
Je zřízen zabezpečený e-mailový systém využívající doménu eu-admin.net. Tato doména s přičleněnými adresami nebude přístupná z umístění mimo celoevropskou doménu sítě TESTA, protože názvy jsou známy pouze na centrálním serveru DNS sítě TESTA, který je stíněný od internetu.
Mapování těchto adres pracovišť sítě TESTA (hostitelské názvy) jejím IP adresám se děje prostřednictvím služby DNS sítě TESTA. Pro každou místní doménu bude do tohoto centrálního serveru DNS sítě TESTA přidán přístup pro elektronickou poštu, který bude předávat všechny elektronické zprávy zaslané na místní domény sítě TESTA do centrálního serveru pro elektronickou poštu (Mail Relay) sítě TESTA. Tento centrální server pro elektronickou poštu sítě TESTA je poté prostřednictvím e-mailových adres místních domén předá konkrétnímu serveru místní domény pro elektronickou poštu. Při tomto způsobu předávání elektronických zpráv budou závažné informace obsažené v elektronických zprávách procházet pouze infrastrukturou celoevropské uzavřené sítě a nikoli nezabezpečeným internetem.
Na pracovištích všech členských států je nezbytné zřídit poddomény (vyznačené tučnou kurzívou ) podle této syntaxe:
„ typ aplikace.pruem.kód členského státu. eu-admin.net“, kde
„ kód členského státu “ je tvořen hodnotou jednopísmenného nebo dvoupísmenného kódu členského státu (např. AT, BE atd.) a
„ typ aplikace “ je tvořen jednou z těchto hodnot: DNA a FP.
V této tabulce jsou uvedeny poddomény pro členské státy za použití zmíněné syntaxe:
|
MS |
Sub Domains |
Comments |
|
BE |
dna.pruem.be.eu-admin.net |
Setting up a secure local link to the existing TESTA II access point |
|
fp.pruem.be.eu-admin.net |
|
|
|
BG |
dna.pruem.bg.eu-admin.net |
|
|
fp.pruem.bg.eu-admin.net |
|
|
|
CZ |
dna.pruem.cz.eu-admin.net |
|
|
fp.pruem.cz.eu-admin.net |
|
|
|
DK |
dna.pruem.dk.eu-admin.net |
|
|
fp.pruem.dk.eu-admin.net |
|
|
|
DE |
dna.pruem.de.eu-admin.net |
Using the existing TESTA II national access points |
|
fp.pruem.de.eu-admin.net |
|
|
|
EE |
dna.pruem.ee.eu-admin.net |
|
|
fp.pruem.ee.eu-admin.net |
|
|
|
IE |
dna.pruem.ie.eu-admin.net |
|
|
fp.pruem.ie.eu-admin.net |
|
|
|
EL |
dna.pruem.el.eu-admin.net |
|
|
fp.pruem.el.eu-admin.net |
|
|
|
ES |
dna.pruem.es.eu-admin.net |
Using the existing TESTA II national access point |
|
fp.pruem.es.eu-admin.net |
|
|
|
FR |
dna.pruem.fr.eu-admin.net |
Using the existing TESTA II national access point |
|
fp.pruem.fr.eu-admin.net |
|
|
|
IT |
dna.pruem.it.eu-admin.net |
|
|
fp.pruem.it.eu-admin.net |
|
|
|
CY |
dna.pruem.cy.eu-admin.net |
|
|
fp.pruem.cy.eu-admin.net |
|
|
|
LV |
dna.pruem.lv.eu-admin.net |
|
|
fp.pruem.lv.eu-admin.net |
|
|
|
LT |
dna.pruem.lt.eu-admin.net |
|
|
fp.pruem.lt.eu-admin.net |
|
|
|
LU |
dna.pruem.lu.eu-admin.net |
Using the existing TESTA II national access point |
|
fp.pruem.lu.eu-admin.net |
|
|
|
HU |
dna.pruem.hu.eu-admin.net |
|
|
fp.pruem.hu.eu-admin.net |
|
|
|
MT |
dna.pruem.mt.eu-admin.net |
|
|
fp.pruem.mt.eu-admin.net |
|
|
|
NL |
dna.pruem.nl.eu-admin.net |
Intending to establish a new TESTA II access point at the NFI |
|
fp.pruem.nl.eu-admin.net |
|
|
|
AT |
dna.pruem.at.eu-admin.net |
Using the existing TESTA II national access point |
|
fp.pruem.at.eu-admin.net |
|
|
|
PL |
dna.pruem.pl.eu-admin.net |
|
|
fp.pruem.pl.eu-admin.net |
|
|
|
PT |
dna.pruem.pt.eu-admin.net |
.... |
|
fp.pruem.pt.eu-admin.net |
.... |
|
|
RO |
dna.pruem.ro.eu-admin.net |
|
|
fp.pruem.ro.eu-admin.net |
|
|
|
SI |
dna.pruem.si.eu-admin.net |
.... |
|
fp.pruem.si.eu-admin.net |
...... |
|
|
SK |
dna.pruem.sk.eu-admin.net |
|
|
fp.pruem.sk.eu-admin.net |
|
|
|
FI |
dna.pruem.fi.eu-admin.net |
[To be inserted] |
|
fp.pruem.fi.eu-admin.net |
|
|
|
SE |
dna.pruem.se.eu-admin.net |
|
|
fp.pruem.se.eu-admin.net |
|
|
|
UK |
dna.pruem.uk.eu-admin.net |
|
|
fp.pruem.uk.eu-admin.net |
|
KAPITOLA 2 Výměna daktyloskopických údajů (dokument o řízení rozhraní)
Cílem následujícího dokumentu o řízení rozhraní je definovat požadavky pro výměnu daktyloskopických informací mezi automatizovanými systémy identifikace otisků prstů (Automated Fingerprint Identification Systems, AFIS) členských států. Vychází z provádění ANSI/NIST-ITL 1-2000 (INT-I, verze 4.22b) Interpolem.
Tato verze pokrývá veškeré základní definice logických záznamů typu 1, typu 2, typu 4, typu 9, typu 13 a typu 15 vyžadované pro daktyloskopické zpracování založené na zobrazení a markantech.
1. Přehled obsahu souboru
Daktyloskopický soubor se skládá z několika logických záznamů. Existuje šestnáct typů záznamů určených v původní normě ANSI/NIST-ITL 1-2000. Mezi každým záznamem a poli a podpoli v rámci záznamů jsou používány odpovídající oddělovací značky ASCII.
Pro výměnu informací mezi výchozí a cílovou agenturou je používáno pouze 6 typů záznamů:
|
typ 1 |
→ |
informace o operaci |
|
typ 2 |
→ |
alfanumerické údaje o osobách nebo případu |
|
typ 4 |
→ |
daktyloskopická zobrazení ve stupních šedi s vysokým rozlišením |
|
typ 9 |
→ |
záznam markantů |
|
typ 13 |
→ |
záznam zobrazení latentního otisku s proměnlivým rozlišením |
|
typ 15 |
→ |
záznam zobrazení otisku dlaně s proměnlivým rozlišením |
1.1 Typ 1 – Záhlaví souboru
Tento záznam obsahuje směrovací informace a informace popisující strukturu zbývající části souboru. Tento typ záznamu rovněž definuje typy operací, které patří do těchto obecných kategorií:
1.2 Typ 2 – Popisný text
Tento záznam obsahuje textovou informaci zajímavou pro odesílající a přijímající agentury.
1.3 Typ 4 – Zobrazení ve stupních šedi s vysokým rozlišením
Tento záznam se používá pro výměnu (osmibitových) daktyloskopických zobrazení ve stupních šedi s vysokým rozlišením nasnímaných v rozlišení 500 pixelů na palec. Daktyloskopická zobrazení jsou komprimována prostřednictvím algoritmu WSQ v poměru maximálně 15:1. Nesmí být používány jiné komprimovací algoritmy ani nezkomprimovaná zobrazení.
1.4 Typ 9 – Záznam markantů
Záznamy typu 9 jsou používány pro výměnu rozdělovacích znaků nebo údajů o markantech. Jejich účelem je jednak zabránit zbytečnému zdvojení kódovacích postupů AFIS, jednak umožnit předávání kódů AFIS, které obsahují méně údajů než příslušná zobrazení.
1.5 Typ 13 – záznam zobrazení latentního otisku s proměnlivým rozlišením
Tento záznam je používán pro výměnu zobrazení latentních otisků prstů s proměnlivým rozlišením a zobrazení latentního otisku dlaně s proměnlivým rozlišením společně s textovými alfanumerickými informacemi. Rozlišení pro snímání zobrazení je 500 pixelů na palec s 256 úrovněmi šedi. Pokud je kvalita zobrazení latentního otisku dostatečná, provede se jeho komprimace pomocí algoritmu WSQ. V případě potřeby může být rozlišení zobrazení na základě dvojstranné dohody zvětšeno na více než 500 pixelů na palec a více než 256 úrovní šedi. V takovém případě se rozhodně doporučuje použít formátu JPEG 2000 (viz příloha 7).
1.6 Záznam zobrazení otisku dlaně s proměnlivým rozlišením
Záznamy zobrazení s přídavným polem typu 15 se používají pro výměnu zobrazení otisku dlaně s proměnlivým rozlišením společně s textovými alfanumerickými informacemi. Rozlišení pro snímání zobrazení je 500 pixelů na palec s 256 úrovněmi šedi. Aby se množství údajů snížilo na minimum, jsou všechna zobrazení otisku dlaně komprimována pomocí algoritmu WSQ. V případě potřeby může být rozlišení zobrazení na základě dvojstranné dohody zvětšeno na více než 500 pixelů na palec a více než 256 úrovní šedi. V takovém případě se rozhodně doporučuje použít formátu JPEG 2000 (viz příloha 7).
2. Formát záznamu
Soubor operace je tvořen jedním nebo více logickými záznamy. Pro každý logický záznam obsažený v souboru je uvedeno několik informačních polí příslušných k danému typu záznamu. Každé informační pole může obsahovat jednu nebo více základních jednovýznamových informačních jednotek. Tyto jednotky dohromady slouží k vyjádření různých aspektů údajů obsažených v daném poli. Informační pole se rovněž může skládat z jedné nebo více informačních jednotek spojených do skupin a v rámci pole vícekrát opakovaných. Taková skupina informačních jednotek se označuje jako podpole. Informační pole může být tudíž tvořeno jedním nebo více podpoli informačních jednotek.
2.1 Oddělovače informací
V logických záznamech přídavných polí je prováděn mechanismus pro vymezení informací za pomoci čtyř oddělovačů informací ASCII. Vymezená informace může představovat jednotky v rámci pole nebo podpole, pole v rámci logického záznamu nebo vícenásobné výskyty podpolí. Tyto oddělovače informací jsou definovány v normě ANSI X3.4. Tyto znaky jsou používány pro logické oddělení a označení informací. Z hlediska hierarchického vztahu je nejobsažnějším oddělovač souboru (File Separator, FS), za ním následuje oddělovač skupiny (Group Separator, GS), oddělovač záznamu (Record Separator, RS) a nakonec oddělovač jednotek (Unit Separator, US). Tabulka 1 uvádí seznam těchto oddělovačů ASCII a popis jejich použití v rámci této normy.
Oddělovače informací by měly být z funkčního hlediska považovány za označení typu údaje, který za nimi následuje. Znak US odděluje individuální informační jednotku v rámci pole nebo podpole. Je to signál, že další informační jednotka je součástí údajů pro dané pole nebo podpole. Vícenásobná podpole v rámci pole oddělená pomocí znaku RS označují začátek další skupiny opakované informační jednotky (opakovaných informačních jednotek). Oddělovač GS použitý mezi informačními poli znamená začátek nového pole a předchází uváděné identifikační číslo pole. Podobně se začátek nového logického záznamu označuje uvedením znaku FS.
Tyto čtyři znaky mají význam pouze tehdy, když jsou použity jako oddělovače údajových jednotek v polích textových záznamů ASCII. Pokud se tyto znaky objevují v záznamech binárních zobrazení a binárních polích, nemají zvláštní význam a jsou jen částí vyměňovaných údajů.
Za normálních okolností by se neměla objevovat prázdná pole nebo prázdné informační jednotky, a proto by mezi jakoukoli dvojicí údajových jednotek měl být pouze jeden oddělovač. Výjimkou z tohoto pravidla jsou případy, kdy údaje v polích nebo v informačních jednotkách v operaci nejsou k dispozici, chybějí, nebo nejsou povinné a zpracování operace není na přítomnosti tohoto určitého údaje závislé. V takových případech se upřednostňuje společné použití vícenásobných a sousedních oddělovačů před vložením fiktivních údajů mezi oddělovače.
Pro definování pole, které se skládá ze tří informačních jednotek, platí následující. Pokud informace pro druhou informační jednotkou schází, potom by se mezi první a třetí informační jednotkou měly objevit dva sousední oddělovače informací US. Pokud chybí druhá i třetí informační jednotka, je třeba použít tři oddělovače – dva znaky US navíc k oddělovači označujícímu konec pole nebo podpole. Obecně, pokud není k dispozici pro pole nebo podpole jedna nebo více povinných či nepovinných informačních jednotek, pak je třeba vložit příslušný počet oddělovačů.
Je možné mít vedle sebe kombinace dvou nebo více znaků ze čtyř dostupných oddělovačů. Pokud chybějí nebo nejsou k dispozici údaje pro informační jednotky, podpole nebo pole, musí být o jeden oddělovač méně než je počet požadovaných údajových jednotek, podpolí nebo polí.
Tabulka 1: Používané oddělovače
|
Code |
Type |
Description |
Hexadecimal Value |
Decimal Value |
|
US |
Unit Separator |
Separates information items |
1F |
31 |
|
RS |
Record Separator |
Separates subfields |
1E |
30 |
|
GS |
Group Separator |
Separates fields |
1D |
29 |
|
FS |
File Separator |
Separates logical records |
1C |
28 |
2.2 Uspořádání záznamu
Pro logické záznamy přídavných polí je třeba každé použité informační pole očíslovat v souladu s touto normou. Formát pro každé pole se skládá z čísla typu logického záznamu, za kterým následuje tečka „.“, z čísla pole, za kterým následuje dvojtečka „:“, a za ním následují příslušné informace pro dané pole. Číslem přídavného pole může být jakákoliv číslice od jedničky do devítky vyskytující se mezi tečkou „.“ a dvojtečkou „:“. Chápe se jako celé číslo pole bez znaménka. Z toho vyplývá, že číslo pole „2.123:“ se rovná a je chápáno stejným způsobem jako číslo pole „2.000000123:“.
Pro názorný příklad je v tomto dokumentu pro vyjmenování polí, která jsou obsažena v každém ze zde popsaných logických záznamů přídavných polí, používáno trojciferného čísla. Čísla polí budou mít podobu „TT.xxx:“, kde „TT“ zastupuje jednoznakový nebo dvouznakový typ záznamu, za kterým následuje tečka. Další tři znaky zahrnují číslo příslušného pole a za nimi následuje dvojtečka. Po dvojtečce následují popisné informace ASCII nebo data zobrazení.
Logické záznamy typu 1 a typu 2 obsahují pouze pole textových údajů ASCII. Celková délka záznamu (včetně čísel polí, dvojteček a oddělovačů) se v každém z těchto typů záznamu zaznamenává jako první pole ASCII. Kontrolní znak oddělovače souboru ASCII „FS“ (označující konec logického záznamu nebo operace) následuje po posledním bytu informace ASCII a počítá se do délky záznamu.
Na rozdíl od pojetí přídavného pole, záznam typu 4 obsahuje pouze binární údaje zaznamenané jako uspořádaná binární pole s pevnou délkou. Celková délka záznamu se zaznamenává v prvním čtyřbytovém binárním poli každého záznamu. Pro tento binární záznam se nezaznamenává ani číslo záznamu následované tečkou, ani identifikační číslo pole následované dvojtečkou. Kromě toho jsou všechny délky pole tohoto záznamu buď pevné, nebo určené, a proto je každý ze čtyř oddělovačů („US“, „RS“, „GS“ nebo „FS“) chápán pouze jen jako binární údaj. Pro binární záznam se jako oddělovač záznamu nebo znak označující konec operace nepoužívá znak „FS“.
3. Logický záznam typu 1: záhlaví souboru
Tento záznam popisuje strukturu souboru, typ souboru a jiné důležité informace. Soubor znaků používaný pro pole typu 1 obsahuje pouze 7bitový kód ANSI pro výměnu informací.
3.1 Pole pro logický záznam typu 1
3.1.1
Toto pole obsahuje údaj o celkovém počtu bytů v celém logickém záznamu typu 1. Formát pole začíná „1.001:“, pak následuje údaj o celkové délce záznamu, která zahrnuje každý znak každého pole a oddělovače informací.
3.1.2
S cílem zajistit, aby uživatelé věděli, která verze normy ANSI/NIST je používána, uvádí toto čtyřbytové pole číslo verze této normy, kterou používá software nebo systém, jež soubor vytvořil. Prvními dvěma byty je určeno referenční číslo hlavní verze, druhými dvěma číslo sekundární revize. Například: původní norma 1986 by byla považována za první verzi a byla by označena jako „0100“, zatímco současná norma ANSI/NIST-ITL 1-2000 jako „0300“.
3.1.3
Toto pole uvádí seznam všech záznamů v souboru podle typu záznamu a pořadí, ve kterém se záznamy v logickém souboru objevují. Skládá se z jednoho nebo více podpolí, z nichž každé postupně obsahuje dvě informační jednotky popisující jeden logický záznam nalezený ve stávajícím souboru. Podpole jsou vkládána ve stejném pořadí, v jakém jsou záznamy zaznamenávány a předávány.
První informační jednotka je v prvním podpoli označena jako „1“, aby odkazovala na tento záznam typu 1. Za ní následuje druhá informační jednotka, která obsahuje počet dalších záznamů obsažených v souboru. Tento počet se rovněž rovná počtu zbývajících podpolí pole 1.003.
Každé zbývající podpole je přiřazeno k jednomu záznamu uvnitř souboru a sekvence podpolí odpovídá sekvenci záznamů. Každé podpole obsahuje dvě informační jednotky. První jednotka určuje typ záznamu. Druhá jednotka představuje znak označující zobrazení (IDC) záznamu. Znak „US“ se používá pro oddělení dvou informačních jednotek.
3.1.4
Toto pole obsahuje mnemotechnický kód složený ze tří písmen, který určuje typ operace. Tyto kódy se mohou lišit od kódů používaných v jiných provedeních normy ANSI/NIST.
CPS: porovnávání otisků souvisejících s trestným činem (Criminal Print-to-Print Search). Tato operace představuje žádost o porovnání záznamu souvisejícího s trestným činem s databází otisků. Otisky osoby musí být do souboru včleněny jako zobrazení komprimovaná pomocí WSQ.
V případě nenalezení shody (No-HIT) budou zaslány tyto logické záznamy:
|
— |
1 záznam typu 1, |
|
— |
1 záznam typu 2. |
V případě nalezení shody (HIT) budou zaslány tyto logické záznamy:
|
— |
1 záznam typu 1, |
|
— |
1 záznam typu 2, |
|
— |
1-14 záznam typu 4. |
Druh operace CPS je shrnut v tabulce A.6.1 (dodatek 6).
PMS: porovnávání otisku s databází latentních otisků (Print-to-Latent Search). Tato operace je používána v případě, že je porovnáván soubor otisků s databází neidentifikovaných latentních otisků. Odpověď bude obsahovat rozhodnutí o shodě/neshodě cílového hledání pomocí systému AFIS. Pokud existuje více neidentifikovaných latentních otisků, bude zasláno více operací SRE, přičemž v každé bude jeden latentní otisk. Otisky osoby musí být do souboru včleněny jako zobrazení komprimovaná pomocí WSQ.
V případě nenalezení shody (No-HIT) budou zaslány tyto logické záznamy:
|
— |
1 záznam typu 1, |
|
— |
1 záznam typu 2. |
V případě nalezení shody (HIT) budou zaslány tyto logické záznamy:
|
— |
1 záznam typu 1, |
|
— |
1 záznam typu 2, |
|
— |
1 záznam typu 13. |
Druh operace PMS je shrnut v tabulce A.6.1 (dodatek 6).
MPS: porovnávání latentního otisku s databází otisků (Latent-to-Print Search). Tato operace se používá v případě porovnávání latentního otisku s databází otisků. Soubor musí zahrnovat informace o latentních markantech a zobrazení (komprimované pomocí WSQ).
V případě nenalezení shody (No-HIT) budou zaslány tyto logické záznamy:
|
— |
1 záznam typu 1, |
|
— |
1 záznam typu 2. |
V případě nalezení shody (HIT) budou zaslány tyto logické záznamy:
|
— |
1 záznam typu 1, |
|
— |
1 záznam typu 2, |
|
— |
1 záznam typu 4 nebo typu 15. |
Druh operace MPS je shrnut v tabulce A.6.4 (dodatek 6).
MMS: porovnávání latentního otisku s latentním otiskem (Latent-to-Latent Search). Při této operaci soubor obsahuje latentní otisk, který je porovnáván s databází neidentifikovaných latentních otisků s cílem stanovit, zda existuje spojitost mezi různými případy trestných činů. Soubor musí zahrnovat informace o latentních markantech a zobrazení (komprimované pomocí WSQ).
V případě nenalezení shody (No-HIT) budou zaslány tyto logické záznamy:
|
— |
1 záznam typu 1, |
|
— |
1 záznam typu 2. |
V případě nalezení shody (HIT) budou zaslány tyto logické záznamy:
|
— |
1 záznam typu 1, |
|
— |
1 záznam typu 2, |
|
— |
1 záznam typu 13. |
Druh operace MMS je shrnut v tabulce A.6.4 (dodatek 6).
SRE: výsledky hledání (Search Results). Tato operace je jako odpověď zaslána agenturou, která obdržela žádosti týkající se daktyloskopie. Odpověď bude obsahovat rozhodnutí o shodě/neshodě cílového hledání pomocí AFIS. Pokud existuje více kandidátů, bude zasláno více operací SRE, přičemž v každé bude jeden kandidát.
Druh operace SRE je shrnut v tabulce A.6.2 (dodatek 6).
ERR: zpráva o chybě (Error Message). Tuto zprávu zasílá cílový systém AFIS, aby ukázal, že při operaci došlo k chybě. Zahrnuje pole zprávy (ERM) ukazující zjištěnou chybu. Budou zaslány tyto logické záznamy:
|
— |
1 záznam typu 1, |
|
— |
1 záznam typu 2. |
Druh operace ERR je shrnut v tabulce A.6.3 (dodatek 6).
Tabulka 2: Přípustné kódy v operacích
|
Transaction Type |
Logical Record Type |
|||||
|
1 |
2 |
4 |
9 |
13 |
15 |
|
|
CPS |
M |
M |
M |
— |
— |
— |
|
SRE |
M |
M |
C |
— (C in case of latent hits) |
C |
C |
|
MPS |
M |
M |
— |
M (1*) |
M |
— |
|
MMS |
M |
M |
— |
M (1*) |
M |
— |
|
PMS |
M |
M |
M* |
— |
— |
M* |
|
ERR |
M |
M |
— |
— |
— |
— |
Vysvětlivky:
|
M |
= |
Povinně |
|
M* |
= |
Může být zahrnut pouze jeden z obou typů záznamů |
|
O |
= |
Nepovinně |
|
C |
= |
Podmíněně, pokud jsou údaje k dispozici |
|
— |
= |
Není přípustné |
|
1* |
= |
Podmíněně v závislosti na předřazených systémech |
3.1.5
V tomto poli je uvedeno datum, kdy byla operace zahájena a které musí být uváděno v souladu se standardním zápisem ISO: RRRRMMDD,
písmena RRRR označují rok, MM měsíc a DD den. U jednociferných čísel se přidávají počáteční nuly. Například „19931004“ označuje den 4. října 1993.
3.1.6
Toto nepovinné pole označuje stupeň naléhavosti žádosti, který se označuje čísly od 1 do 9. „1“ označuje největší naléhavost a „9“ nejmenší naléhavost. Operace označené stupněm naléhavosti „1“ jsou zpracovávány bez prodlení.
3.1.7
Toto pole uvádí cílovou agenturu operace.
Identifikátor sestává ze dvou informačních jednotek v tomto formátu: CC/agentura.
První informační jednotka obsahuje kód země (Country Code, CC) podle normy ISO 3166, který se skládá ze dvou alfanumerických znaků. Druhá jednotka, agentura, je volným textovým označením agentury s maximální délkou 32 alfanumerických znaků.
3.1.8
Toto pole uvádí odesílatele souboru a má stejný formát jako pole pro DAI (pole 1007).
3.1.9
Toto pole uvádí kontrolní číslo pro referenční účely. Číslo je generováno počítačem v tomto formátu: RRSSSSSSSSA,
písmena RR představují rok operace, SSSSSSSS je osmiciferné pořadové číslo a A je kontrolní znak generovaný podle postupu uvedeného v dodatku 2.
Pokud není TCN k dispozici, je formát RRSSSSSSSS vyplněn nulami a kontrolním znakem generovaným podle výše uvedeného postupu.
3.1.10
V případě odpovědi na zaslanou žádost bude toto nepovinné pole obsahovat kontrolní číslo operace žádosti. Toto pole má proto stejný formát jako TCN (pole 1.009).
3.1.11
Toto pole uvádí normální rozlišení snímání systému podporovaného původcem operace. Toto rozlišení je určeno dvojciferným číslem, za kterým následuje desetinná tečka a dvě další číslice.
Pro všechny operace podle rozhodnutí 2008/615/SVV se skenuje v rozlišení 500 pixelů na palec nebo 19,68 pixelů/mm.
3.1.12
Toto pětibytové pole udává nominální rozlišení, použité při přenosu zobrazení. Toto rozlišení se vyjadřuje v pixelech/mm ve stejném formátu jako v poli NSR (pole 1.011).
3.1.13
Toto povinné pole uvádí doménový název pro provedení logického záznamu typu 2, které definuje uživatel. Skládá se ze dvou informačních jednotek a mělo by být „INT-I{US}4.22{GS}“.
3.1.14
Tímto povinným polem je stanoven mechanismus vyjadřování data a času prostřednictvím univerzálních jednotek greenwichského středního času (GMT). Je-li využito, pole GMT obsahuje univerzální datum, jež se stanovuje spolu s místním datem uvedeným v poli 1.005 (DAT). Použitím pole GMT se odstraňují nesrovnalosti mezi údaji o místním čase v případech, kdy dochází k přenosu operace a odpovědi na ni mezi dvěma místy oddělenými několika časovými pásmy. GMT udává univerzální datum a čas ve 24hodinovém formátu nezávisle na časových pásmech. Znázorňuje se jako řetězec „CCRRMMDDHHMMSSZ“; jedná se o posloupnost 15 znaků vyjadřujících datum a GMT, přičemž posledním znakem je písmeno „Z“. Znaky „CCRR“ vyjadřují rok, znaky „MM“ vyjadřují měsíc v desítkách a jednotkách, znaky „DD“ vyjadřují den dotyčného měsíce v desítkách a jednotkách, znaky „HH“ vyjadřují hodinu, znaky „MM“ minutu a znaky „SS“ sekundu příslušné operace. Úplné datum není pozdější než datum stávající.
4. Logický záznam typu 2: Popisný text
Struktura tohoto záznamu není v původní normě ANSI/NIST z převážné části definována. Záznam obsahuje informace, jež mají pro agentury odesílající či přijímající dotyčný soubor zvláštní význam. Pro zajištění kompatibility komunikujících daktyloskopických systémů je třeba, aby záznam obsahoval pouze pole uvedená níže. V tomto dokumentu je stanoveno, která pole jsou povinná a která jsou nepovinná, a rovněž je v něm definována struktura jednotlivých polí.
4.1 Pole pro logický záznam typu 2
4.1.1
Toto povinné pole obsahuje délku uvedeného záznamu typu 2 a stanoví celkový počet bytů, zahrnující každý znak obsažený v každém poli záznamu a oddělovače informace.
4.1.2
IDC obsažený v tomto povinném poli je vyjádřením IDC podle ASCII, jak je definován v poli obsahu souboru (CNT) záznamu typu 1 (pole 1.003).
4.1.3
Toto pole je povinné a obsahuje čtyři byty udávající verzi INT-I, s níž je tento konkrétní záznam typu 2 ve shodě.
Prvními dvěma byty je určeno číslo hlavní verze, druhými dvěma číslo sekundární revize. Toto provádění je například založeno na INT-I verzi 4 revizi 22 a bylo by vyjádřeno jako „0422“.
4.1.4
Toto číslo připisuje místní daktyloskopický úřad souboru latentních otisků nalezených na místě činu. Používá se tento formát: CC/číslo,
kde CC je kód země používaný Interpolem o délce dvou alfanumerických znaků a číslo odpovídá příslušným místním pokynům a může sestávat až ze 32 alfanumerických znaků.
Toto pole umožňuje systému identifikovat latentní otisky týkající se konkrétního trestného činu.
4.1.5
Toto číslo udává každou sekvenci latentních otisků v rámci případu. Může sestávat až ze čtyř numerických znaků. Sekvence je latentní otisk nebo série latentních otisků seskupených pro účely archivace nebo zkoumání. Z uvedené definice vyplývá, že sekvenční číslo bude třeba přiřadit i jednotlivým latentním otiskům.
Toto pole spolu s MID (pole 2.009) lze použít pro účely identifikace konkrétního latentního otisku v rámci sekvence.
4.1.6
Tento identifikátor udává jednotlivý latentní otisk v rámci sekvence. Identifikátor nabývá hodnot vyjádřených jedním či dvěma písmeny, přičemž prvnímu latentnímu otisku je přiřazeno písmeno „A“, druhému písmeno „B“ atd., až do nejvyšší hodnoty „ZZ“. Použití tohoto pole je analogické k použití sekvenčního čísla otisku, o němž se pojednává v popisu SQN (pole 2.008).
4.1.7
Jedná se o jedinečné referenční číslo přidělené agenturou členského státu osobě, jež je poprvé obviněna ze spáchání trestného činu. V rámci jedné země nemá žádná osoba více než jedno CRN ani je nesdílí s žádnou jinou osobou. Jedna osoba však může mít referenční čísla pachatele v několika zemích, přičemž tato čísla bude možno rozlišit pomocí kódu země.
Pro pole CRN se používá tento formát: CC/číslo,
kde CC je kód země definovaný v normě ISO 3166 o délce dvou alfanumerických znaků a číslo odpovídá příslušným vnitrostátním pokynům vydávající agentury a může sestávat až ze 32 alfanumerických znaků.
V případech operací podle rozhodnutí 2008/615/SVV se toto pole použije pro vnitrostátní referenční číslo pachatele vydané agenturou původu a spojené se zobrazeními v záznamech typu 4 nebo typu 15.
4.1.8
Toto pole obsahuje CRN (pole 2.010) předávané operací CPS či PMS bez hlavního kódu země.
4.1.9
Toto pole obsahuje CNO (pole 2.007) předávané operací MPS či MMS bez hlavního kódu země.
4.1.10
Toto pole obsahuje SQN (pole 2.008) předávané operací MPS či MMS.
4.1.11
Toto pole obsahuje MID (pole 2.009) předávané operací MPS či MMS.
4.1.12
V případě operace SRE na žádost PMS jsou v tomto poli uvedeny informace o prstu, jenž je předmětem případné shody (HIT). Formát tohoto pole je následující:
NN, kde NN je kód pozice prstu definovaný v tabulce 5 a sestávající ze dvou číslic.
Ve všech ostatních případech je toto pole nepovinné. Může dosahovat délky až 32 alfanumerických znaků a poskytovat další informace týkající se žádosti.
4.1.13
Toto pole obsahuje minimálně dvě podpole. První podpole popisuje typ vyhledávání, jež bylo provedeno, a používá mnemotechnické kódy složené ze tří písmen udávající typ operace v TOT (pole 1.004). Druhé podpole obsahuje jediný znak. Znak „I“ se použije k označení nalezené shody (HIT), znak „N“ se použije k vyjádření toho, že nebyly nalezeny žádné shodné případy (NOHIT). Třetí podpole obsahuje sekvenční identifikátor pro výsledek týkající se kandidátů a celkový počet kandidátů oddělený lomítkem. Existuje-li více kandidátů, dojde k zaslání více zpráv.
V případě možné shody (HIT) čtvrté podpole obsahuje výsledek dosahující délky až šesti číslic. Došlo-li k potvrzení shody (HIT), hodnota tohoto podpole se stanoví jako „999999“.
Příklad: „CPS{RS}I{RS}001/001{RS}999999{GS}“
Pokud vzdálený AFIS nepřipisuje výsledky, použije se na příslušném místě výsledek rovnající se nule.
4.1.14
Toto pole obsahuje zprávy o chybách, jež jsou výsledkem transakcí a jež budou zaslány zpět žadateli jakožto součást chybové operace.
Tabulka 3: Zprávy o chybách
|
Numeric Code (1-3) |
Meaning (5-128) |
|
003 |
ERROR: UNAUTHORISED ACCESS |
|
101 |
Mandatory field missing |
|
102 |
Invalid record type |
|
103 |
Undefined field |
|
104 |
Exceed the maximum occurrence |
|
105 |
Invalid number of subfields |
|
106 |
Field length too short |
|
107 |
Field length too long |
|
108 |
Field is not a number as expected |
|
109 |
Field number value too small |
|
110 |
Field number value too big |
|
111 |
Invalid character |
|
112 |
Invalid date |
|
115 |
Invalid item value |
|
116 |
Invalid type of transaction |
|
117 |
Invalid record data |
|
201 |
ERROR: INVALID TCN |
|
501 |
ERROR: INSUFFICIENT FINGERPRINT QUALITY |
|
502 |
ERROR: MISSING FINGERPRINTS |
|
503 |
ERROR: FINGERPRINT SEQUENCE CHECK FAILED |
|
999 |
ERROR: ANY OTHER ERROR. FOR FURTHER DETAILS CALL DESTINATION AGENCY. |
Zpráva o chybě v rozmezí 100 až 199:
Tyto zprávy o chybách se týkají ověření záznamů ANSI/NIST a jsou definovány takto:
<error_code 1>: IDC <idc_number 1> FIELD <field_id 1> <dynamic text 1> LF
<error_code 2>: IDC <idc_number 2> FIELD <field_id 2> <dynamic text 2>...
kde
|
— |
error_code je kód výhradně spojený s konkrétním důvodem (viz tabulka 3), |
|
— |
field_id je číslo nesprávného pole podle číslování ANSI/NIST (např. 1.001, 2.001,...) ve formátu <record_type>.<field_id>.<sub_field_id>, |
|
— |
dynamický text poskytuje podrobnější popis chyby, |
|
— |
LF je posun o řádek (Line Feed) oddělující chyby, pokud se jich vyskytne více než jedna, |
|
— |
pro záznam typu 1 se ICD stanoví jako „–1“. |
Příklad:
201: IDC –1 FIELD 1.009 WRONG CONTROL CHARACTER {LF} 115: IDC 0 FIELD 2.003 INVALID SYSTEM INFORMATION
Toto pole je pro chybové operace povinné.
4.1.15
Toto pole obsahuje maximální množství kandidátů k ověření předpokládané žádající agenturou. Hodnota ENC nesmí překročit hodnoty stanovené v tabulce 11.
5. Logický záznam typu 4: Zobrazení ve stupních šedi ve vysokém rozlišení
Je třeba vzít na vědomí, že záznamy typu 4 jsou oproti ASCII ve své podstatě binární. Každému poli je proto v rámci záznamu přiřazena zvláštní pozice, z čehož plyne, že všechna pole jsou povinná.
Norma umožňuje stanovit v rámci záznamu velikost i rozlišení daného zobrazení. Vyžaduje, aby logické záznamy typu 4 obsahovaly údaje o daktyloskopickém zobrazení, jež se předává v nominálním rozlišení 500 až 520 pixelů na palec. U nových typů je preferovaná hodnota rozlišení na úrovni 500 pixelů na palec čili 19,68 pixelů na milimetr. 500 pixelů na palec je rozlišení stanovené v INT-I, avšak podobné systémy spolu mohou komunikovat za použití nepreferovaných hodnot v rozsahu 500 až 520 pixelů na palec.
5.1 Pole pro logický záznam typu 4
5.1.1
Toto čtyřbytové pole obsahuje délku uvedeného záznamu typu 4 a stanoví celkový počet bytů, zahrnující každý byte obsažený v každém poli záznamu.
5.1.2
Jedná se o jednobytové binární vyjádření čísla IDC uvedeného v souboru záhlaví.
5.1.3
Typ otisku je jednobytové pole využívající šestý byte záznamu.
Tabulka 4: Typ otisku prstu
|
Code |
Description |
|
0 |
Live-scan of plain fingerprint |
|
1 |
Live-scan of rolled fingerprint |
|
2 |
Non-live scan impression of plain fingerprint captured from paper |
|
3 |
Non-live scan impression of rolled fingerprint captured from paper |
|
4 |
Latent impression captured directly |
|
5 |
Latent tracing |
|
6 |
Latent photo |
|
7 |
Latent lift |
|
8 |
Swipe |
|
9 |
Unknown |
5.1.4
Toto pole s pevnou délkou 6 bytů využívá pozice sedmého až dvanáctého bytu záznamu typu 4. Obsahuje možné pozice prstu počínaje bytem umístěným nejvíce vlevo (7. byte záznamu). Známá či nejpravděpodobnější pozice prstu se přebírá z tabulky 5. Lze provést odkaz až na pět dalších prstů, a to zanesením různých pozicí prstu do zbývajících 5 bytů za použití stejného formátu. Má-li být využito méně než pět odkazů na pozici prstu, nevyužité byty se vyplní binárně 255. Pro odkaz na všechny pozice prstu se použije kód 0 označující hodnotu „neznámý“.
Tabulka 5: Kód pozice prstu a maximální velikost
|
Finger position |
Finger code |
Width (mm) |
Length (mm) |
|
Unknown |
0 |
40,0 |
40,0 |
|
Right thumb |
1 |
45,0 |
40,0 |
|
Right index finger |
2 |
40,0 |
40,0 |
|
Right middle finger |
3 |
40,0 |
40,0 |
|
Right ring finger |
4 |
40,0 |
40,0 |
|
Right little finger |
5 |
33,0 |
40,0 |
|
Left thumb |
6 |
45,0 |
40,0 |
|
Left index finger |
7 |
40,0 |
40,0 |
|
Left middle finger |
8 |
40,0 |
40,0 |
|
Left ring finger |
9 |
40,0 |
40,0 |
|
Left little finger |
10 |
33,0 |
40,0 |
|
Plain right thumb |
11 |
30,0 |
55,0 |
|
Plain left thumb |
12 |
30,0 |
55,0 |
|
Plain right four fingers |
13 |
70,0 |
65,0 |
|
Plain left four fingers |
14 |
70,0 |
65,0 |
Pro latentní otisky z místa činu by měly být používány pouze kódy 0 až 10.
5.1.5
Toto jednobytové pole využívá 13. byte záznamu typu 4. Obsahuje-li „0“, bylo zobrazení naskenováno v preferovaném rozlišení 19,68 pixelů/mm (500 pixelů na palec). Obsahuje-li „1“, bylo zobrazení naskenováno v jiném rozlišení podle údajů v záznamu typu 1.
5.1.6
Toto pole využívá bytů 14 a 15 v záznamu typu 4. Udává počet pixelů obsažených v každé skenované linii. Nejvýznamnější bude první byte.
5.1.7
Toto pole zaznamenává v bytech 16 a 17 počet skenovaných linií v daném zobrazení. Nejvýznamnější je první byte.
5.1.8
Toto jednobytové pole udává algoritmus komprese ve stupních šedi použité k zakódování údajů o daném zobrazení. Pro takovéto použití binární kód 1 udává, že došlo k použití komprese WSQ (dodatek 7).
5.1.9
Toto pole obsahuje bytový řetězec představující dané zobrazení. Jeho struktura bude přirozeně záviset na použitém algoritmu komprese.
6. Logický záznam typu 9: Záznam markantů
Záznamy typu 9 obsahují text ASCII popisující markanty a související informace ve formě kódů z latentního otisku. Pro operaci vyhledávání latentních otisků neexistuje žádné omezení pro tyto záznamy typu 9 v souboru, přičemž každý záznam slouží pro odlišný náhled či latentní otisk.
6.1 Získávání markantů
6.1.1
Touto normou jsou definována identifikační čísla sloužící k popisu typu markantů. Ta jsou uvedena v tabulce 6. Konec papilární linie je označen jako typ 1. Vidlice je označena jako typ 2. Nelze-li markant jednoznačně zařadit do jednoho z výše uvedených typu, označí se jako „jiný“, typ 0.
Tabulka 6: Typy markantů
|
Type |
Description |
|
0 |
Other |
|
1 |
Ridge ending |
|
2 |
Bifurcation |
6.1.2
Aby vzory odpovídaly oddílu 5 normy ANSI INCITS 378-2004, použije se pro stanovení umístění (pozice a úhlu natočení) jednotlivých markantů následující metoda.
Pozicí či polohou markantu představujícího konec papilární linie se rozumí bod rozdvojení ústřední struktury okolní oblasti bezprostředně před koncem linie. Pokud by tři větve okolní oblasti byly zúženy na struktury o šířce jediného pixelu, jejich průsečík bude představovat polohu markantu. Podobně je polohou markantu v případě vidlice bod, kde dochází k rozdělení ústřední struktury linie. Pokud by tři větve linie byly zúženy na struktury o šířce jediného pixelu, průsečík těchto tří větví bude představovat polohu markantu.
Po převedení všech konců na vidlice jsou všechny markanty daktyloskopického zobrazení vyjádřeny jako vidlice. Souřadnice X a Y označující pixely průsečíku tří větví každého markantu lze přímo formátovat. Z každé strukturální vidlice lze odvodit úhel natočení markantu. Tři větve každé strukturální vidlice je třeba přezkoumat a stanovit koncový bod každé větve. Obrázek 6.1.2 ilustruje tři metody používané pro stanovení konce větve na základě skenu o rozlišení 500 pixelů na palec.
Konec se určí na základě toho, ke kterému jevu dojde dříve. Počet pixelů je založen na skenu o rozlišení 500 pixelů na palec. Důsledkem použití skenů o jiných rozlišeních by byly jiné počty pixelů.
|
— |
vzdálenost 0,064 palce (32. pixel), |
|
— |
délka větve struktury, jež spadá mezi vzdálenost 0,02 palce a 0,064 palce (10. až 32. pixel), kratší větve se nepoužijí, |
|
— |
v rámci vzdálenosti 0,064 palce (32. pixel) se vyskytuje druhá vidlice. |
Obrázek 6.1.2
Úhel markantu se stanoví pomocí konstrukce tří virtuálních paprsků vycházejících z bodu vidlice a procházejících koncem každé větve. Osa nejmenšího z těchto tří úhlů tvořených uvedenými paprsky udává úhel natočení markantu.
6.1.3
Systémem souřadnic používaným k vyjádření markantů otisku prstu je kartézský souřadnicový systém. Pozice markantů jsou vyjádřeny jejich souřadnicemi x a y. Počátkem systému souřadnic je levý horní roh původního zobrazení, přičemž hodnoty x narůstají směrem doprava a hodnoty y klesají směrem dolů. Souřadnice markantu x a y se vyjadřují v jednotkách pixelů od počátku. Je třeba mít na paměti, že umístění počátku a jednotky měření neodpovídají metodě použité v definicích typu 9 v ANSI/NIST-ITL 1-2000.
6.1.4
Úhly se vyjadřují ve standardním matematickém formátu, kde úhel o velikosti nula stupňů směřuje doprava a velikost úhlů roste proti směru hodinových ručiček. Zaznamenané úhly směřují v případě konce linie zpět podél této linie a v případě vidlice ke středu okolní oblasti. Tato metoda využívá úhly pootočené o 180 stupňů oproti metodě popsané v definicích typu 9 v ANSI/NIST-ITL 1-2000.
6.2 Pole pro logický záznam typu 9, formát INCITS-378
Všechna pole typu 9 se zaznamenávají jako text ASCII. V tomto přídavné poli záznamu nejsou povolena žádná binární pole.
6.2.1
Toto povinné ASCII pole obsahuje délku logického záznamu a stanoví celkový počet bytů, zahrnující každý znak obsažený v každém poli záznamu.
6.2.2
Toto povinné dvoubytové pole se používá pro identifikaci a stanovení polohy údajů markantů. IDC obsažené v tomto poli odpovídá IDC nalezenému v poli obsahu souboru záznamu typu 1.
6.2.3
Toto povinné jednobytové pole popisuje způsob získání informací týkajících se daktyloskopického zobrazení. Do tohoto pole se zanáší hodnota ASCII vlastního kódu zvolená z tabulky 4 pro označení typu otisku.
6.2.4
Toto pole obsahuje znak „U“ pro označení, že markanty jsou formátovány podle normy M1-378. Ačkoliv informace mohou být kódovány v souladu s normou M1-378, veškerá pole typu 9 s údaji musí zůstat jakožto textová pole ASCII.
6.2.5
Toto pole obsahuje tři informační jednotky. První informační jednotka obsahuje hodnotu „27“ (0x1B). Jedná se o identifikaci majitele formátu CBEFF přidělenou Mezinárodním sdružením biometrického průmyslu (IBIA) technickému výboru M1 INCITS. Znak <US> tuto položku odděluje od CBEFF typu formátu, jemuž je připsána hodnota „513“ (0x0201), jež udává, že tento záznam obsahuje pouze údaje o poloze a úhlu natočení bez jakýchkoli informací týkajících se třídy rozšířených údajů. Znak <US> tuto položku odděluje od CBEFF identifikátoru produktu (PID), jímž se uvádí „vlastník“ kódovacího zařízení. Tuto hodnotu stanoví prodejce. Je-li zaslána, lze ji získat z internetové stránky IBIA (www.ibia.org).
6.2.6
Toto pole obsahuje dvě informační jednotky oddělené znakem <US>. První z nich nabývá hodnoty „APPF“, jestliže zařízení použité pro zhotovení původního zobrazení bylo osvědčeno jako vyhovující dodatku F (údaje o kvalitě zobrazení IAFIS, 29. ledna 1999) CJIS-RS-0010, pokynů pro elektronický přenos otisků prstů Federálního úřadu pro vyšetřování. Pokud zařízení nebylo vyhovující, bude obsahovat hodnotu „NONE“. Druhá informační jednotka obsahuje identifikační číslo záznamového zařízení, což je číslo produktu přidělené záznamovému zařízení prodejcem. Hodnota „0“ uvádí, že identifikační číslo záznamového zařízení není nahlášeno.
6.2.7
Toto povinné ASCII pole udává počet pixelů obsažených v jedné vodorovné linii přenášeného zobrazení. Maximální vodorovný rozměr je omezen na 65 534 pixelů.
6.2.8
Toto povinné ASCII pole udává počet vodorovných linií obsažených v přenášeném zobrazení. Maximální svislý rozměr je omezen na 65 534 pixelů.
6.2.9
Toto povinné ASCII pole udává jednotky použité k popisu frekvence vzorkování zobrazení (hustoty pixelů). Hodnota „1“ v tomto poli udává pixely na palec, hodnota „2“ udává pixely na centimetr. Hodnota „0“ v tomto poli označuje, že rozestup není udán. V takovém případě se poměr rozmístění pixelů odvodí z poměru HPS/VPS.
6.2.10
Toto povinné ASCII pole udává celým číslem hustotu pixelů ve vodorovném směru v případě, že SLC obsahuje hodnotu „1“ nebo „2“. Jinak označuje vodorovnou složku poměru rozmístění pixelů.
6.2.11
Toto povinné ASCII pole udává celým číslem hustotu pixelů ve svislém směru v případě, že SLC obsahuje hodnotu „1“ nebo „2“. Jinak označuje svislou složku poměru rozmístění pixelů.
6.2.12
Toto povinné pole obsahuje číslo zobrazení prstu přiřazeného k údajům tohoto záznamu. Číslo zobrazení začíná hodnotou „0“ a zvyšuje se po jedné až k hodnotě „15“.
6.2.13
Toto pole obsahuje kód udávající pozici prstu, z něhož plynou informace v tomto záznamu typu 9. Pozice prstu či dlaně se udává prostřednictvím kódu v hodnotě mezi 1 a 10 z tabulky 5 nebo příslušného kódu dlaně z tabulky 10.
6.2.14
Toto pole udává kvalitu celkových údajů o markantech prstu a nabývá hodnoty mezi 0 a 100. Toto číslo je celkovým vyjádřením kvality záznamu o prstu a udává kvalitu původního zobrazení, získaných markantů a jakékoli další operace, jež mohou záznam markantů ovlivnit.
6.2.15
Toto povinné pole udává počet markantů zanesených v tomto logickém záznamu.
6.2.16
Toto pole obsahuje šest informačních složek oddělených znakem <US>. Sestává z několika podpolí, z nichž každé obsahuje podrobnosti o jediném markantu. Celkový počet podpolí týkajících se markantů musí odpovídat údaji uvedeném v poli 136. První informační jednotka obsahuje pořadové číslo markantu, jež začíná hodnotou „1“ a pro každý další markant otisku prstu se zvyšuje o „1“. Druhá a třetí informační jednotka obsahují souřadnice „x“ a „y“ daného markantu v jednotkách pixelů. Čtvrtou informační jednotkou je úhel markantu zaznamenaný v jednotkách dvou stupňů. Tato hodnota je nezáporná a pohybuje se mezi 0 a 179. Pátou informační jednotkou je typ markantu. Hodnota „0“ udává markant typu „OTHER“ (JINÝ), hodnota „1“ konec papilární linie a hodnota „2“ vidlici. Šestá informační jednotka udává kvalitu každého markantu. Tato hodnota se pohybuje mezi 1 jako minimem a 100 jako maximem. Hodnota „0“ uvádí, že hodnota kvality není k dispozici. Každé podpole se od následujícího odděluje za použití oddělovacího znaku <RS>.
6.2.17
Toto pole sestává z řady podpolí, z nichž každé obsahuje tři informační jednotky. První informační jednotka prvního podpole udává metodu stanovení počtu papilárních linií. Hodnota „0“ udává, že metodu stanovení počtu papilárních linií ani jejich pořadí v záznamu nelze určit. Hodnota „2“ udává, že pro každý centrální markant byly údaje o počtu papilárních linií převedeny do nejbližších sousedících markantů ve čtyřech kvadrantech a počty papilárních linií jsou u každého centrálního markantu uvedeny společně. Hodnota „2“ udává, že pro každý centrální markant byly údaje o počtu papilárních linií převedeny do nejbližších sousedících markantů v osmi oktantech a počty papilárních linií jsou u každého centrálního markantu uvedeny společně. Obě zbývající informační jednotky prvního podpole nabývají hodnoty „0“. Informační jednotky jsou vzájemně odděleny oddělovacím znakem <US>. Následující podpole budou obsahovat pořadové číslo centrálního markantu coby první informační jednotku, pořadové číslo sousedícího markantu coby druhou informační jednotku a počet zkřížených papilárních linií coby třetí informační jednotku. Podpole jsou vzájemně oddělena oddělovacím znakem <RS>.
6.2.18
Toto pole bude obsahovat jedno podpole pro každý vrchol zaznamenaný v původním zobrazení. Každé podpole obsahuje tři informační jednotky. První dvě jednotky obsahují souřadnice „x“ a „y“ v jednotkách pixelů. Třetí informační jednotka obsahuje úhel vrcholu zaznamenaný v jednotkách dvou stupňů. Tato hodnota je nezáporná a pohybuje se mezi 0 a 179. Různé vrcholy jsou vzájemně odděleny oddělovacím znakem <RS>.
6.2.19
Toto pole bude obsahovat jedno podpole pro každou deltu zaznamenanou v původním zobrazení. Každé podpole obsahuje tři informační jednotky. První dvě jednotky obsahují souřadnice „x“ a „y“ v jednotkách pixelů. Třetí informační jednotka obsahuje úhel delty zaznamenaný v jednotkách dvou stupňů. Tato hodnota je nezáporná a pohybuje se mezi 0 a 179. Různé vrcholy jsou vzájemně odděleny oddělovacím znakem <RS>.
7. Záznam typu 13 – zobrazení latentního otisku s proměnlivým rozlišením
Logický záznam typu 13 s přídavným polem obsahuje údaje o zobrazení získané ze zobrazení latentních otisků. Tato zobrazení mají být předána agenturám, jež z nich automaticky získají informace o potřebných znacích nebo k jejich získání použijí manuální postup.
Informace týkající se rozlišení použitého při skenování, velikosti zobrazení a dalších parametrů nezbytných pro zpracování daného zobrazení se zaznamenávají jako přídavná pole v rámci záznamu.
Tabulka 7: Záznam typu 13 ohledně zobrazení latentního otisku s proměnlivým rozlišením
|
Ident |
Cond. code |
Field Number |
Field Name |
Char type |
Field size per occurrence |
Occur count |
Max byte count |
||
|
min. |
max. |
min |
max |
||||||
|
LEN |
M |
13.001 |
LOGICAL RECORD LENGTH |
N |
4 |
8 |
1 |
1 |
15 |
|
IDC |
M |
13.002 |
IMAGE DESIGNATION CHARACTER |
N |
2 |
5 |
1 |
1 |
12 |
|
IMP |
M |
13.003 |
IMPRESSION TYPE |
A |
2 |
2 |
1 |
1 |
9 |
|
SRC |
M |
13.004 |
SOURCE AGENCY/ORI |
AN |
6 |
35 |
1 |
1 |
42 |
|
LCD |
M |
13.005 |
LATENT CAPTURE DATE |
N |
9 |
9 |
1 |
1 |
16 |
|
HLL |
M |
13.006 |
HORIZONTAL LINE LENGTH |
N |
4 |
5 |
1 |
1 |
12 |
|
VLL |
M |
13.007 |
VERTICAL LINE LENGTH |
N |
4 |
5 |
1 |
1 |
12 |
|
SLC |
M |
13.008 |
SCALE UNITS |
N |
2 |
2 |
1 |
1 |
9 |
|
HPS |
M |
13.009 |
HORIZONTAL PIXEL SCALE |
N |
2 |
5 |
1 |
1 |
12 |
|
VPS |
M |
13.010 |
VERTICAL PIXEL SCALE |
N |
2 |
5 |
1 |
1 |
12 |
|
CGA |
M |
13.011 |
COMPRESSION ALGORITHM |
A |
5 |
7 |
1 |
1 |
14 |
|
BPX |
M |
13.012 |
BITS PER PIXEL |
N |
2 |
3 |
1 |
1 |
10 |
|
FGP |
M |
13.013 |
FINGER POSITION |
N |
2 |
3 |
1 |
6 |
25 |
|
RSV |
|
13.014 13.019 |
RESERVED FOR FUTURE DEFINITION |
— |
— |
— |
— |
— |
— |
|
COM |
O |
13.020 |
COMMENT |
A |
2 |
128 |
0 |
1 |
135 |
|
RSV |
|
13.021 13.199 |
RESERVED FOR FUTURE DEFINITION |
— |
— |
— |
— |
— |
— |
|
UDF |
O |
13.200 13.998 |
USER-DEFINED FIELDS |
— |
— |
— |
— |
— |
— |
|
DAT |
M |
13.999 |
IMAGE DATA |
B |
2 |
— |
1 |
1 |
— |
Vysvětlivky k typu znaků: N = numerický; A = alfabetický; AN = alfanumerický; B = binární.
7.1 Pole pro logický záznam typu 13
Níže jsou popsány údaje obsažené v každém z polí logického záznamu typu 13.
V rámci logického záznamu typu 13 se položky uvádějí v číslovaných polích. Je třeba, aby první dvě pole záznamu zachovávala pořadí, přičemž pole obsahující údaje o zobrazení je posledním fyzickým polem záznamu. Pro každé pole záznamu typu 13 je v tabulce 7 uveden „kód podmínky“ jakožto povinný „M“, nebo nepovinný „O“, číslo pole, název pole, typ znaku, velikost pole a omezení výskytu. Na základě trojmístného čísla pole se v posledním sloupci udává pro dané pole maximální počet bytů. S rostoucím počtem číslic použitých pro číslo pole poroste rovněž maximální počet bytů. Dvě položky v rámci „velikosti pole podle výskytu“ (field size per occurrence) zahrnují všechny oddělovače znaků použité v tomto poli. „Maximální počet bytů“ (maximum byte count) zahrnuje číslo pole, informace a všechny oddělovače znaků včetně znaku „GS“.
7.1.1
Toto povinné ASCII pole obsahuje údaj o celkovém počtu bytů v logickém záznamu typu 13. Pole 13.001 udává celkovou délku záznamu, která zahrnuje každý znak každého pole v rámci záznamu a oddělovače informací.
7.1.2
Toto povinné ASCII pole se použije ke stanovení údajů o zobrazení latentního otisku v daném záznamu. IDC v tomto poli odpovídá IDC nalezenému v poli obsahu souboru (CNT) záznamu typu 1.
7.1.3
Toto povinné jednobytové či dvoubytové ASCII pole udává způsob získání informací týkajících se zobrazení latentního otisku. Do tohoto pole se zanese příslušný kód latentního otisku zvolený z tabulky 4 (prst) nebo z tabulky 9 (dlaň).
7.1.4
Toto povinné ASCII pole obsahuje identifikační údaje úřadu či organizace, jež původně zaznamenala zobrazení obličeje, jež záznam obsahuje. V tomto poli bude obvykle identifikátor zdrojové agentury (ORI) patřící agentuře, jež zobrazení zaznamenala. Identifikátor sestává ze dvou informačních jednotek v následujícím formátu: CC/agentura.
První informační jednotka obsahuje kód země používaný Interpolem o délce dvou alfanumerických znaků. Druhá jednotka, agentura, je volný text obsahující identifikační údaje agentury o maximální délce 32 alfanumerických znaků.
7.1.5
Toto povinné ASCII pole obsahuje datum zaznamenání zobrazení latentního otisku v daném záznamu. Datum se udává v osmi číslicích ve formátu CCRRMMDD. Znaky „CCRR“ vyjadřují rok záznamu daného zobrazení; znaky „MM“ vyjadřují měsíc v desítkách a jednotkách; znaky „DD“ vyjadřují den dotyčného měsíce v desítkách a jednotkách. Například 20000229 znamená datum 29. února 2000. Souhrnné údaje o datu musejí udávat platné datum.
7.1.6
Toto povinné ASCII pole udává počet pixelů obsažených v jedné vodorovné linii přenášeného zobrazení.
7.1.7
Toto povinné ASCII pole udává počet vodorovných linií obsažených v přenášeném zobrazení.
7.1.8
Toto povinné ASCII pole udává jednotky použité k popisu frekvence vzorkování zobrazení (hustoty pixelů). Hodnota „1“ v tomto poli udává pixely na palec, hodnota „2“ udává pixely na centimetr. Hodnota „0“ v tomto poli označuje, že rozestup není udán. V takovém případě se poměr rozmístění pixelů odvodí z poměru HPS/VPS.
7.1.9
Toto povinné ASCII pole udává celým číslem hustotu pixelů ve vodorovném směru v případě, že SLC obsahuje hodnotu „1“ nebo „2“. Jinak označuje vodorovnou složku poměru rozmístění pixelů.
7.1.10
Toto povinné ASCII pole udává celým číslem hustotu pixelů ve svislém směru v případě, že SLC obsahuje hodnotu „1“ nebo „2“. Jinak označuje svislou složku poměru rozmístění pixelů.
7.1.11
Toto povinné ASCII pole udává algoritmus použitý pro kompresi zobrazení ve stupních šedi. Pro kódy kompresí viz tabulku 7.
7.1.12
Toto povinné ASCII pole udává počet bitů použitých pro vyjádření pixelu. Toto pole obsahuje hodnotu „8“ pro normální hodnoty stupňů šedi od „0“ do „255“. Jakákoli hodnota vyšší než „8“ zanesená v tomto poli představuje pixel vyjadřující odstín šedi se zvýšenou přesností.
7.1.13
Toto povinné přídavné pole obsahuje jednu či více možných pozicí prstu nebo dlaně, jež mohou odpovídat zobrazení latentního otisku. Číslo kódu v desítkové soustavě odpovídající známé či nejpravděpodobnější pozici prstu se přebírá z tabulky 5, číslo odpovídající nejpravděpodobnější pozici dlaně z tabulky 10; zanáší se jako podpole ASCII o délce jednoho či dvou znaků. Lze uvést odkaz na další pozice prstu nebo dlaně, a to uvedením odlišných kódů pro pozice jako podpolí oddělených oddělovacím znakem „RS“. Pro každou pozici prstu od jedničky do desítky se použije kód „0“ pro „neznámý prst“. Pro každou pozici otisku dlaně se použije kód „20“ pro „neznámá dlaň“.
7.1.14
Tato pole jsou vyhrazena pro zahrnutí do budoucích revizí této normy. V této úrovni revize se žádná z těchto polí nepoužijí. Vyskytují-li se některá z těchto polí, je třeba je ignorovat.
7.1.15
Tohoto nepovinného pole lze využít pro zanesení komentářů nebo jiných informací v podobě ASCII textu k údajům o zobrazení latentního otisku.
7.1.16
Tato pole jsou vyhrazena pro zahrnutí do budoucích revizí této normy. V této úrovni revize se žádná z těchto polí nepoužijí. Vyskytují-li se některá z těchto polí, je třeba je ignorovat.
7.1.17
Tato pole mohou být definována uživatelem a budou použita pro budoucí požadavky. Jejich velikost a obsah určuje uživatel tak, aby byly v souladu s přijímající agenturou. Vyskytnou-li se, obsahují tato pole informace v podobě ASCII textu.
7.1.18
Toto pole obsahuje veškerá data zaznamenaného zobrazení latentního otisku. Vždy se mu přidělí číslo pole 999 a vždy se musí jednat o poslední pole záznamu. Po údaji „13.999:“ například následují data tvořící zobrazení v binárním vyjádření.
Každý pixel dat stupňů šedi, jež nebyly podrobeny kompresi, se obvykle kvantuje do osmi bitů (256 stupňů šedé) obsažených v jediném bytu. Je-li hodnota v BPX poli 13.012 vyšší nebo nižší než „8“, bude počet bytů nezbytných pro záznam jednoho pixelu odlišný. Při použití komprese data pixelů procházejí kompresí v souladu s kompresním postupem uvedeným v poli GCA.
7.2 Konec záznamu typu 13 – zobrazení latentního otisku s proměnlivým rozlišením
Pro účely konzistentnosti se bezprostředně po posledním bytu dat z pole 13.999 použije oddělovač „FS“ pro oddělení od následujícího logického záznamu. Tento oddělovač musí být obsažen v poli udávajícím délku v rámci záznamu typu 13.
8. Záznam typu 15 – zobrazení otisku dlaně s proměnlivým rozlišením
Logický záznam typu 15 s přídavným polem obsahuje data zobrazení otisku dlaně a používá se k jejich výměně, spolu s pevnými a uživatelský definovanými poli obsahujícími textové informace týkající se digitálního zobrazení. Informace týkající se rozlišení použitého při skenování, velikosti zobrazení a dalších parametrů či komentáře nezbytné pro zpracování daného zobrazení se zaznamenávají jako přídavná pole v rámci záznamu. Zobrazení otisků dlaní předávaná jiným agenturám zpracují přijímající agentury s cílem získat informace o potřebných znacích pro potřeby srovnání.
Data zobrazení se získávají přímo od subjektu za použití přímého skenovacího zařízení nebo z dlaňové daktyloskopické karty či z jiného média obsahujícího otisky dlaní subjektu.
Jakákoli metoda získání zobrazení otisků dlaní musí být schopná zaznamenat soubor zobrazení pro každou ruku. Tento soubor obsahuje malíkovou hranu jako jediné skenované zobrazení a celou oblast otevřené dlaně od zápěstí po špičky prstů jako jedno či dvě skenovaná zobrazení. Jsou-li pro zaznamenání celé dlaně použita dvě zobrazení, spodní z nich pokrývá oblast od zápěstí po vrchol meziprstní oblasti (třetí prstní kloub) a zahrnuje thenární i hypothenární oblast dlaně. Horní zobrazení sahá od spodní strany meziprstní oblasti až k nejvzdálenějším špičkám prstů. Tím je zajištěna dostatečná míra překrytí obou zobrazení, neboť obě zahrnují meziprstní oblast dlaně. Porovnáním papilárních struktur a podrobností nacházejících se v této společné oblasti může osoba provádějící přezkum s jistotou prohlásit, že obě zobrazení pocházejí z téže dlaně.
Protože operace týkající se dlaně může být použita pro různé účely, může zahrnovat jedno či více zobrazení jedinečných oblastí zaznamenaných z dlaně či ruky. Úplný soubor záznamů týkajících se dlaní bude obvykle obsahovat zobrazení malíkové hrany a jedno či více zobrazení dlaně, a to u obou rukou. Protože logický záznam typu 15 s přídavným polem může obsahovat pouze jedno binární pole, bude pro každou malíkovou hranu třeba jednoho záznamu typu 15 a pro každou celou dlaň jednoho či dvou záznamů typu 15. U obvyklé operace týkající se dlaní bude tedy pro zaznamenání otisků dlaní subjektu třeba čtyř až šesti záznamů typu 15.
8.1 Pole pro logický záznam typu 15
Níže jsou popsány údaje obsažené v každém z polí logického záznamu typu 15.
V rámci logického záznamu typu 15 se položky uvádějí v číslovaných polích. Je třeba, aby první dvě pole záznamu zachovávala pořadí, přičemž pole obsahující údaje o zobrazení je posledním fyzickým polem záznamu. Pro každé pole záznamu typu 15 je v tabulce 8 uveden „kód podmínky“ jakožto povinný „M“, nebo nepovinný „O“, číslo pole, název pole, typ znaku, velikost pole a omezení výskytu. Na základě trojmístného čísla pole se v posledním sloupci udává pro dané pole maximální počet bytů. S rostoucím počtem číslic použitých pro číslo pole poroste rovněž maximální počet bytů. Dvě položky v rámci „velikosti pole podle výskytu“ (field size per occurrence) zahrnují všechny oddělovače znaků použité v tomto poli. „Maximální počet bytů“ (maximum byte count) zahrnuje číslo pole, informace a všechny oddělovače znaků včetně znaku „GS“.
8.1.1
Toto povinné ASCII pole obsahuje údaj o celkovém počtu bytů v logickém záznamu typu 15. Pole 15.001 udává celkovou délku záznamu, která zahrnuje každý znak každého pole v rámci záznamu a oddělovače informací.
8.1.2
Toto povinné ASCII pole se použije ke stanovení zobrazení otisku dlaně v daném záznamu. IDC v tomto poli odpovídá IDC nalezenému v poli obsahu souboru (CNT) záznamu typu 1.
8.1.3
Toto povinné jednobytové ASCII pole popisuje způsob získání informací týkajících se zobrazení dlaně. Do tohoto pole se zanese příslušný kód zvolený z tabulky 9.
8.1.4
Toto povinné ASCII pole obsahuje identifikační údaje úřadu či organizace, jež původně zaznamenala zobrazení obličeje, jež záznam obsahuje. V tomto poli bude obvykle identifikátor zdrojové agentury (ORI) patřící agentuře, jež zobrazení zaznamenala. Identifikátor sestává ze dvou informačních jednotek v tomto formátu: CC/agentura.
První informační jednotka obsahuje kód země používaný Interpolem o délce dvou alfanumerických znaků. Druhá jednotka, agentura, je volný text obsahující identifikační údaje agentury o maximální délce 32 alfanumerických znaků.
8.1.5
Toto povinné ASCII pole obsahuje datum zaznamenání zobrazení otisku dlaně. Datum se udává v osmi číslicích ve formátu CCRRMMDD. Znaky „CCRR“ vyjadřují rok záznamu daného zobrazení; znaky „MM“ vyjadřují měsíc v desítkách a jednotkách; znaky „DD“ vyjadřují den dotyčného měsíce v desítkách a jednotkách. Například záznam 20000229 znamená datum 29. února 2000. Souhrnné údaje o datu musejí udávat platné datum.
8.1.6
Toto povinné ASCII pole udává počet pixelů obsažených v jedné vodorovné linii přenášeného zobrazení.
8.1.7
Toto povinné ASCII pole udává počet vodorovných linií obsažených v přenášeném zobrazení.
8.1.8
Toto povinné ASCII pole udává jednotky použité k popisu frekvence vzorkování zobrazení (hustoty pixelů). Hodnota „1“ v tomto poli udává pixely na palec, hodnota „2“ udává pixely na centimetr. Hodnota „0“ v tomto poli označuje, že rozestup není udán. V takovém případě se poměr rozmístění pixelů odvodí z poměru HPS/VPS.
8.1.9
Toto povinné ASCII pole udává celým číslem hustotu pixelů ve vodorovném směru v případě, že SLC obsahuje hodnotu „1“ nebo „2“. Jinak označuje vodorovnou složku poměru rozmístění pixelů.
8.1.10
Toto povinné ASCII pole udává celým číslem hustotu pixelů ve svislém směru v případě, že SLC obsahuje hodnotu „1“ nebo „2“. Jinak označuje svislou složku poměru rozmístění pixelů.
Tabulka 8: Záznam typu 15 – zobrazení otisku dlaně s proměnlivým rozlišením
|
Ident |
Cond. code |
Field Number |
Field Name |
Char type |
Field size per occurrence |
Occur count |
Max byte count |
||
|
min. |
max. |
min |
max |
||||||
|
LEN |
M |
15.001 |
LOGICAL RECORD LENGTH |
N |
4 |
8 |
1 |
1 |
15 |
|
IDC |
M |
15.002 |
IMAGE DESIGNATION CHARACTER |
N |
2 |
5 |
1 |
1 |
12 |
|
IMP |
M |
15.003 |
IMPRESSION TYPE |
N |
2 |
2 |
1 |
1 |
9 |
|
SRC |
M |
15.004 |
SOURCE AGENCY/ORI |
AN |
6 |
35 |
1 |
1 |
42 |
|
PCD |
M |
15.005 |
PALMPRINT CAPTURE DATE |
N |
9 |
9 |
1 |
1 |
16 |
|
HLL |
M |
15.006 |
HORIZONTAL LINE LENGTH |
N |
4 |
5 |
1 |
1 |
12 |
|
VLL |
M |
15.007 |
VERTICAL LINE LENGTH |
N |
4 |
5 |
1 |
1 |
12 |
|
SLC |
M |
15.008 |
SCALE UNITS |
N |
2 |
2 |
1 |
1 |
9 |
|
HPS |
M |
15.009 |
HORIZONTAL PIXEL SCALE |
N |
2 |
5 |
1 |
1 |
12 |
|
VPS |
M |
15.010 |
VERTICAL PIXEL SCALE |
N |
2 |
5 |
1 |
1 |
12 |
|
CGA |
M |
15.011 |
COMPRESSION ALGORITHM |
AN |
5 |
7 |
1 |
1 |
14 |
|
BPX |
M |
15.012 |
BITS PER PIXEL |
N |
2 |
3 |
1 |
1 |
10 |
|
PLP |
M |
15.013 |
PALMPRINT POSITION |
N |
2 |
3 |
1 |
1 |
10 |
|
RSV |
|
15.014 15.019 |
RESERVED FOR FUTURE INCLUSION |
— |
— |
— |
— |
— |
— |
|
COM |
O |
15.020 |
COMMENT |
AN |
2 |
128 |
0 |
1 |
128 |
|
RSV |
|
15.021 15.199 |
RESERVED FOR FUTURE INCLUSION |
— |
— |
— |
— |
— |
— |
|
UDF |
O |
15.200 15.998 |
USER-DEFINED FIELDS |
— |
— |
— |
— |
— |
— |
|
DAT |
M |
15.999 |
IMAGE DATA |
B |
2 |
— |
1 |
1 |
— |
Tabulka 9: Typ otisku dlaně
|
Description |
Code |
|
Live-scan palm |
10 |
|
Nonlive-scan palm |
11 |
|
Latent palm impression |
12 |
|
Latent palm tracing |
13 |
|
Latent palm photo |
14 |
|
Latent palm lift |
15 |
8.1.11
Toto povinné ASCII pole udává algoritmus použitý pro kompresi zobrazení ve stupních šedi. Záznam o hodnotě „NONE“ v tomto poli udává, že data obsažená v příslušném záznamu nejsou komprimována. U zobrazení, jež mají být komprimována, toto pole obsahuje preferovanou metodu komprimace zobrazení otisků deseti prstů. Platné kódy komprimace jsou stanoveny v dodatku 7.
8.1.12
Toto povinné ASCII pole udává počet bitů použitých pro vyjádření pixelu. Toto pole obsahuje hodnotu „8“ pro normální hodnoty stupňů šedi od „0“ do „255“. Jakákoli hodnota vyšší nebo nižší než „8“ zanesená v tomto poli představuje pixel vyjadřující odstín šedi se zvýšenou či sníženou přesností.
Tabulka 10: Kódy, oblasti a velikosti týkající se dlaní
|
Palm Position |
Palm code |
Image area (mm2) |
Width (mm) |
Height (mm) |
|
Unknown Palm |
20 |
28 387 |
139,7 |
203,2 |
|
Right Full Palm |
21 |
28 387 |
139,7 |
203,2 |
|
Right Writer s Palm |
22 |
5 645 |
44,5 |
127,0 |
|
Left Full Palm |
23 |
28 387 |
139,7 |
203,2 |
|
Left Writer s Palm |
24 |
5 645 |
44,5 |
127,0 |
|
Right Lower Palm |
25 |
19 516 |
139,7 |
139,7 |
|
Right Upper Palm |
26 |
19 516 |
139,7 |
139,7 |
|
Left Lower Palm |
27 |
19 516 |
139,7 |
139,7 |
|
Left Upper Palm |
28 |
19 516 |
139,7 |
139,7 |
|
Right Other |
29 |
28 387 |
139,7 |
203,2 |
|
Left Other |
30 |
28 387 |
139,7 |
203,2 |
8.1.13
Toto povinné přídavné pole obsahuje pozici dlaně, jež odpovídá zobrazení otisku dlaně. Číslo kódu v desítkové soustavě odpovídající známé či nejpravděpodobnější pozici dlaně se přebírá z tabulky 10; zanáší se jako podpole ASCII o délce dvou znaků. V tabulce 10 jsou rovněž uvedeny maximální oblasti a rozměry pro každou možnou pozici otisku dlaně.
8.1.14
Tato pole jsou vyhrazena pro zahrnutí do budoucích revizí této normy. V této úrovni revize se žádná z těchto polí nepoužijí. Vyskytují-li se některá z těchto polí, je třeba je ignorovat.
8.1.15
Tohoto nepovinného pole lze využít pro zanesení komentářů nebo jiných informací v podobě ASCII textu k údajům o zobrazení otisku dlaně.
8.1.16
Tato pole jsou vyhrazena pro zahrnutí do budoucích revizí této normy. V této úrovni revizí se žádná z těchto polí nepoužijí. Vyskytují-li se některá z těchto polí, je třeba je ignorovat.
8.1.17
Tato pole mohou být definována uživatelem a budou použita pro budoucí požadavky. Jejich velikost a obsah určuje uživatel tak, aby byly v souladu s přijímající agenturou. Vyskytnou-li se, obsahují tato pole informace v podobě ASCII textu.
8.1.18
Toto pole obsahuje veškerá data zaznamenaného zobrazení otisku dlaně. Vždy se mu přidělí číslo pole 999 a vždy se musí jednat o poslední pole záznamu. Po údaji „15.999:“ například následují data tvořící zobrazení v binárním vyjádření. Každý pixel dat stupňů šedi, jež nebyly podrobeny kompresi, se obvykle kvantuje do osmi bitů (256 stupňů šedé) obsažených v jediném bytu. Je-li hodnota BPX poli 15.012 vyšší nebo nižší než „8“, bude počet bytů nezbytných pro záznam jednoho pixelu odlišný. Při použití komprese data pixelů procházejí kompresí v souladu s kompresním postupem uvedeným v poli CGA.
8.2 Konec záznamu typu 13 – zobrazení otisku dlaně s proměnlivým rozlišením
Pro účely konzistentnosti se bezprostředně po posledním bytu dat z pole 15.999 použije oddělovač „FS“ pro oddělení od následujícího logického záznamu. Tento oddělovač musí být obsažen v poli udávajícím délku v rámci záznamu typu 15.
8.3 Další záznamy typu 15 – zobrazení otisku dlaně s proměnlivým rozlišením
Soubor může obsahovat další záznamy typu 15. Pro každé další zobrazení otisku dlaně je nezbytný úplný logický záznam typu 15 s oddělovačem „FS“.
Tabulka 11: Maximální množství kandidátů přijatých k ověření na jeden přenos
|
Type of AFIS Search |
TP/TP |
LT/TP |
LP/PP |
TP/UL |
LT/UL |
PP/ULP |
LP/ULP |
|
Maximum Number of Candidates |
1 |
10 |
5 |
5 |
5 |
5 |
5 |
Typy vyhledávání:
|
|
TP/TP: porovnávání sad otisků deseti prstů (ten-print against ten-print) |
|
|
LT/TP: porovnávání latentního otisku prstu se sadou otisků deseti prstů (fingerprint latent against ten-print) |
|
|
LP/PP: porovnávání latentního otisku dlaně s otiskem dlaně (palmprint latent against palmprint) |
|
|
TP/UL: porovnávání sady otisků deseti prstů s nevyřešeným latentním otiskem prstu (ten-print against unsolved fingerprint latent) |
|
|
LT/UL: porovnávání latentního otisku prstu s nevyřešeným latentním otiskem prstu (fingerprint latent against unsolved fingerprint latent) |
|
|
PP/ULP: porovnávání otisku dlaně s nevyřešeným latentním otiskem dlaně (palmprint against unsolved palmprint latent) |
|
|
LP/ULP: porovnávání latentního otisku dlaně s nevyřešeným latentním otiskem dlaně (palmprint latent against unsolved palmprint latent) |
9. Dodatky ke kapitole 2 (výměna daktyloskopických údajů)
9.1 Dodatek 1 ASCII kódy oddělovačů
|
ASCII |
Position (2) |
Description |
|
LF |
1/10 |
Separates error codes in field 2.074 |
|
FS |
1/12 |
Separates logical records of a file |
|
GS |
1/13 |
Separates fields of a logical record |
|
RS |
1/14 |
Separates the subfields of a record field |
|
US |
1/15 |
Separates individual information items of the field or subfield |
9.2 Dodatek 2 Výpočet alfanumerického kontrolního znaku
Pro TCN a TCR (pole 1.09 a 1.10):
Číslo odpovídající kontrolnímu znaku se získá pomocí následujícího vzorce:
(RR * 108 + SSSSSSSS) Modulo 23
Znak RR představuje numerickou hodnotu posledních dvou číslic roku a znak SSSSSSSS numerickou hodnotu sériového čísla.
Kontrolní znak je pak odvozen z referenční tabulky uvedené níže.
Pro CRO (pole 2.010)
Číslo odpovídající kontrolnímu znaku se získá pomocí následujícího vzorce:
(RR* 106 + NNNNNN) Modulo 23
Znak RR představuje numerickou hodnotu posledních dvou číslic roku a znak NNNNNN numerickou hodnotu sériového čísla.
Kontrolní znak je pak odvozen z referenční tabulky uvedené níže.
Referenční tabulka kontrolních znaků
|
1-A |
9-J |
17-T |
|
2-B |
10-K |
18-U |
|
3-C |
11-L |
19-V |
|
4-D |
12-M |
20-W |
|
5-E |
13-N |
21-X |
|
6-F |
14-P |
22-Y |
|
7-G |
15-Q |
0-Z |
|
8-H |
16-R |
|
9.3 Dodatek 3 Znakové kódy
7bitový kód ANSI pro výměnu informací
|
ASCII Character Set |
||||||||||
|
+ |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
30 |
|
|
|
! |
„ |
# |
$ |
% |
& |
‚ |
|
40 |
( |
) |
* |
+ |
, |
- |
. |
/ |
0 |
1 |
|
50 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
: |
; |
|
60 |
< |
= |
> |
? |
@ |
A |
B |
C |
D |
E |
|
70 |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
|
80 |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
|
90 |
Z |
[ |
\ |
] |
^ |
_ |
` |
a |
b |
c |
|
100 |
d |
e |
f |
g |
h |
i |
j |
k |
l |
m |
|
110 |
n |
o |
p |
q |
r |
s |
t |
u |
v |
w |
|
120 |
x |
y |
z |
{ |
| |
} |
~ |
|
|
|
9.4 Dodatek 4 Přehled operací
Záznam typu 1 (povinný)
|
Identifier |
Field Number |
Field Name |
CPS/PMS |
SRE |
ERR |
|
LEN |
1.001 |
Logical Record Length |
M |
M |
M |
|
VER |
1.002 |
Version Number |
M |
M |
M |
|
CNT |
1.003 |
File Content |
M |
M |
M |
|
TOT |
1.004 |
Type of Transaction |
M |
M |
M |
|
DAT |
1.005 |
Date |
M |
M |
M |
|
PRY |
1.006 |
Priority |
M |
M |
M |
|
DAI |
1.007 |
Destination Agency |
M |
M |
M |
|
ORI |
1.008 |
Originating Agency |
M |
M |
M |
|
TCN |
1.009 |
Transaction Control Number |
M |
M |
M |
|
TCR |
1.010 |
Transaction Control Reference |
C |
M |
M |
|
NSR |
1.011 |
Native Scanning Resolution |
M |
M |
M |
|
NTR |
1.012 |
Nominal Transmitting Resolution |
M |
M |
M |
|
DOM |
1.013 |
Domain name |
M |
M |
M |
|
GMT |
1.014 |
Greenwich mean time |
M |
M |
M |
Ve sloupci podmínek:
O = nepovinné; M = povinné; C = podmíněné, pokud je operace odpovědí původní agentuře
Záznam typu 2 (povinný)
|
Identifier |
Field Number |
Field Name |
CPS/PMS |
MPS/MMS |
SRE |
ERR |
|
LEN |
2.001 |
Logical Record Length |
M |
M |
M |
M |
|
IDC |
2.002 |
Image Designation Character |
M |
M |
M |
M |
|
SYS |
2.003 |
System Information |
M |
M |
M |
M |
|
CNO |
2.007 |
Case Number |
— |
M |
C |
— |
|
SQN |
2.008 |
Sequence Number |
— |
C |
C |
— |
|
MID |
2.009 |
Latent Identifier |
— |
C |
C |
— |
|
CRN |
2.010 |
Criminal Reference Number |
M |
— |
C |
— |
|
MN1 |
2.012 |
Miscellaneous Identification Number |
— |
— |
C |
C |
|
MN2 |
2.013 |
Miscellaneous Identification Number |
— |
— |
C |
C |
|
MN3 |
2.014 |
Miscellaneous Identification Number |
— |
— |
C |
C |
|
MN4 |
2.015 |
Miscellaneous Identification Number |
— |
— |
C |
C |
|
INF |
2.063 |
Additional Information |
O |
O |
O |
O |
|
RLS |
2.064 |
Respondents List |
— |
— |
M |
— |
|
ERM |
2.074 |
Status/Error Message Field |
— |
— |
— |
M |
|
ENC |
2.320 |
Expected Number of Candidates |
M |
M |
— |
— |
Ve sloupci podmínek:
O = nepovinné; M = povinné; C = podmíněné, pokud jsou údaje k dispozici
|
* |
= |
pokud je přenos dat v souladu s vnitrostátními právními předpisy (nevztahuje se na něj rozhodnutí 2008/615/SVV) |
9.5 Dodatek 5 Definice záznamu typu 1
|
Identifier |
Condition |
Field Number |
Field Name |
Character Type |
Example Data |
|
LEN |
M |
1.001 |
Logical Record Length |
N |
1.001:230{GS} |
|
VER |
M |
1.002 |
Version Number |
N |
1.002:0300{GS} |
|
CNT |
M |
1.003 |
File Content |
N |
1.003:1{US}15{RS}2{US}00{RS}4{US}01{RS}4{US}02{RS}4{US}03{RS}4{US}04{RS}4{US}05{RS}4{US}06{RS}4{US}07{RS}4{US}08{RS}4{US}09{RS}4{US}10{RS}4{US}11{RS}4{US}12{RS}4{US}13{RS}4{US}14{GS} |
|
TOT |
M |
1.004 |
Type of Transaction |
A |
1.004:CPS{GS} |
|
DAT |
M |
1.005 |
Date |
N |
1.005:20050101{GS} |
|
PRY |
M |
1.006 |
Priority |
N |
1.006:4{GS} |
|
DAI |
M |
1.007 |
Destination Agency |
1* |
1.007:DE/BKA{GS} |
|
ORI |
M |
1.008 |
Originating Agency |
1* |
1.008:NL/NAFIS{GS} |
|
TCN |
M |
1.009 |
Transaction Control Number |
AN |
1.009:0200000004F{GS} |
|
TCR |
C |
1.010 |
Transaction Control Reference |
AN |
1.010:0200000004F{GS} |
|
NSR |
M |
1.011 |
Native Scanning Resolution |
AN |
1.011:19.68{GS} |
|
NTR |
M |
1.012 |
Nominal Transmitting Resolution |
AN |
1.012:19.68{GS} |
|
DOM |
M |
1.013 |
Domain Name |
AN |
1.013: INT-I{US}4.22{GS} |
|
GMT |
M |
1.014 |
Greenwich Mean Time |
AN |
1.014:20050101125959Z |
Ve sloupci podmínek: O = nepovinné, M = povinné, C = podmíněné
Ve sloupci znakového typu: A = alfa, N = numerický, B = binární
1* povolené znaky pro název agentury jsou [„0.9“, „A.Z“, „a.z“, „_“,“.“, „ „, „-“]
9.6 Dodatek 6 Definice záznamu typu 2
Tabulka A.6.1: Operace CPS a PMS
|
Identifier |
Condition |
Field Number |
Field Name |
Character Type |
Example Data |
|
LEN |
M |
2.001 |
Logical Record Length |
N |
2.001:909{GS} |
|
IDC |
M |
2.002 |
Image Designation Character |
N |
2.002:00{GS} |
|
SYS |
M |
2.003 |
System Information |
N |
2.003:0422{GS} |
|
CRN |
M |
2.010 |
Criminal Reference Number |
AN |
2.010:DE/E999999999{GS} |
|
INF |
O |
2.063 |
Additional Information |
1* |
2.063:Additional Information 123{GS} |
|
ENC |
M |
2.320 |
Expected Number of Candidates |
N |
2.320:1{GS} |
Tabulka A.6.2: Operace SRE
|
Identifier |
Condition |
Field Number |
Field Name |
Character Type |
Example Data |
|
LEN |
M |
2.001 |
Logical Record Length |
N |
2.001:909{GS} |
|
IDC |
M |
2.002 |
Image Designation Character |
N |
2.002:00{GS} |
|
SYS |
M |
2.003 |
System Information |
N |
2.003:0422{GS} |
|
CRN |
C |
2.010 |
Criminal Reference Number |
AN |
2.010:NL/2222222222{GS} |
|
MN1 |
C |
2.012 |
Miscellaneous Identification Number |
AN |
2.012:E999999999{GS} |
|
MN2 |
C |
2.013 |
Miscellaneous Identification Number |
AN |
2.013:E999999999{GS} |
|
MN3 |
C |
2.014 |
Miscellaneous Identification Number |
N |
2.014:0001{GS} |
|
MN4 |
C |
2.015 |
Miscellaneous Identification Number |
A |
2.015:A{GS} |
|
INF |
O |
2.063 |
Additional Information |
1* |
2.063:Additional Information 123{GS} |
|
RLS |
M |
2.064 |
Respondents List |
AN |
2.064:CPS{RS}I{RS}001/001{RS}999999{GS} |
Tabulka A.6.3: Operace ERR
|
Identifier |
Condition |
Field Number |
Field Name |
Character Type |
Example Data |
|
LEN |
M |
2.001 |
Logical Record Length |
N |
2.001:909{GS} |
|
IDC |
M |
2.002 |
Image Designation Character |
N |
2.002:00{GS} |
|
SYS |
M |
2.003 |
System Information |
N |
2.003:0422{GS} |
|
MN1 |
M |
2.012 |
Miscellaneous Identification Number |
AN |
2.012:E999999999{GS} |
|
MN2 |
C |
2.013 |
Miscellaneous Identification Number |
AN |
2.013:E999999999{GS} |
|
MN3 |
C |
2.014 |
Miscellaneous Identification Number |
N |
2.014:0001{GS} |
|
MN4 |
C |
2.015 |
Miscellaneous Identification Number |
A |
2.015:A{GS} |
|
INF |
O |
2.063 |
Additional Information |
1* |
2.063:Additional Information 123{GS} |
|
ERM |
M |
2.074 |
Status/Error Message Field |
AN |
2.074: 201: IDC - 1 FIELD 1.009 WRONG CONTROL CHARACTER {LF} 115: IDC 0 FIELD 2.003 INVALID SYSTEM INFORMATION {GS} |
Tabulka A.6.4: Operace MPS a MMS
|
Identifier |
Condition |
Field Number |
Field Name |
Character Type |
Example Data |
|
LEN |
M |
2.001 |
Logical Record Length |
N |
2.001:909{GS} |
|
IDC |
M |
2.002 |
Image Designation Character |
N |
2.002:00{GS} |
|
SYS |
M |
2.003 |
System Information |
N |
2.003:0422{GS} |
|
CNO |
M |
2.007 |
Case Number |
AN |
2.007:E999999999{GS} |
|
SQN |
C |
2.008 |
Sequence Number |
N |
2.008:0001{GS} |
|
MID |
C |
2.009 |
Latent Identifier |
A |
2.009:A{GS} |
|
INF |
O |
2.063 |
Additional Information |
1* |
2.063:Additional Information 123{GS} |
|
ENC |
M |
2.320 |
Expected Number of Candidates |
N |
2.320:1{GS} |
Ve sloupci podmínek: O = nepovinné, M = povinné, C = podmíněné
Ve sloupci znakového typu: A = alfa, N = numerický, B = binární
1* povolené znaky jsou [„0.9“, „A.Z“, „a.z“, „_“,“.“, „ „, „-“, „ „]
9.7 Dodatek 7 Komprimační kódy pro data ve stupních šedi
Komprimační kódy
|
Compression |
Value |
Remarks |
|
Wavelet Scalar Quantization Grayscale Fingerprint Image Compression Specification IAFIS-IC-0010(V3), dated December 19, 1997 |
WSQ |
Algorithm to be used for the compression of grayscale images in Type-4, Type-7 and Type-13 to Type-15 records. Shall not be used for resolutions > 500dpi. |
|
JPEG 2000 [ISO 15444/ITU T.800] |
J2K |
To be used for lossy and losslessly compression of grayscale images in Type-13 to Type-15 records. Strongly recommended for resolutions > 500 dpi |
9.8 Dodatek 8 Upřesnění zprávy
V zájmu zlepšení vnitřního fungování systému by měl být v předmětu zprávy operace podle Prümské smlouvy uveden kód země (CC) daného členského státu, který zprávu posílá, a typ operace (TOT pole 1.004).
Formát: Kód země/typ operace
Příklad: „DE/CPS“
Část pro obsah zprávy může zůstat prázdná.
KAPITOLA 3 Výměna údajů o registraci vozidel
1. Společný soubor údajů pro automatizované vyhledávání údajů o registraci vozidel
1.1 Definice
Definice povinných datových prvků a nepovinných datových prvků podle čl. 16 odst. 4 zní takto:
Povinné (M):
Datové prvky musí být sděleny, pokud jsou informace k dispozici v národním registru členského státu. Výměna informací je tedy povinná, pokud jsou tyto informace k dispozici.
Nepovinné (O):
Datové prvky mohou být sděleny, pokud jsou informace dostupné v národním registru členského státu. Výměna informací tedy není povinná, ani když jsou informace k dispozici.
Pokud je prvek určen jako významný z hlediska rozhodnutí 2008/615/SVV, je každý takový prvek v souboru údajů označen (Y).
1.2 Vyhledávání vozidla, vlastníka nebo držitele
1.2.1
Existují dva různé způsoby pro vyhledávání těchto informací uvedené v následujícím odstavci:
|
— |
podle čísla podvozku (VIN), referenčního data a času (nepovinné), |
|
— |
podle státní poznávací značky, čísla podvozku (VIN) (nepovinné), referenčního data a času (nepovinné). |
Pomocí těchto kritérií pro vyhledávání budou oznámeny informace o jednom vozidle, a někdy i o více vozidlech. Pokud mají být oznámeny informace pouze o jednom vozidlu, všechny položky jsou oznámeny v jedné odpovědi. Je-li nalezeno více vozidel než jedno, dožádaný členský stát může sám určit, které položky oznámí; všechny položky, nebo pouze položky pro upřesnění vyhledávání (například z důvodu ochrany soukromí nebo z důvodů týkajících se provedení).
Položky nutné k upřesnění vyhledávání jsou uvedeny v bodě 1.2.2.1. V bodě 1.2.2.2 je popsán úplný soubor informací.
Provádí-li se vyhledávání podle čísla povozku a referenčního data a času, může toto vyhledávání provádět jeden nebo všechny zúčastněné členské státy.
Provádí-li se vyhledávání podle čísla řidičského průkazu a referenčního data a času, musí ho provádět jeden konkrétní členský stát.
Obvykle se při vyhledávání používá skutečné datum a čas, je však možné provádět vyhledávání na základě referenčního data a času v minulosti. Provádí-li se vyhledávání na základě referenčního data a času v minulosti a informace z minulých let nejsou v registru konkrétního členského státu k dispozici, protože žádné takové informace vůbec nejsou registrovány, lze poskytnout aktuální informace a uvést, že se jedná o aktuální informace.
1.2.2
|
1.2.2.1 |
Položky k upřesnění vyhledávání, které mají být oznámeny
|
|
1.2.2.2 |
Úplný soubor údajů
|
2. Zabezpečení údajů
2.1 Přehled
Softwarová aplikace EUCARIS předává zabezpečené sdělení ostatním členským státům a komunikuje se záložními předřazenými systémy členských států za pomoci XML. Členské státy si vyměňují zprávy tak, že je přímo zasílají příjemci. Datové centrum členského státu je propojeno se sítí Evropské unie TESTA.
Zprávy XML posílané přes tuto síť jsou kódovány. Metoda používaná ke kódování těchto zpráv je SSL. Zprávy zasílané do záložních systémů jsou zprávy ve formátu XML v podobě prostého textu, jelikož spojení mezi aplikací a záložním systémem musí probíhat ve chráněném prostředí.
Je k dispozici klientská aplikace, kterou lze používat v rámci členského státu pro hledání ve vlastním registru nebo v registrech jiných členských států. Klienti budou rozpoznáni na základě uživatelského jména a hesla nebo klientského certifikátu. Spojení s uživatelem může být kódováno, avšak odpovědnost za takové kódování nese každý členský stát.
2.2 Bezpečnostní prvky týkající se výměny zpráv
Model zabezpečení je založen na kombinaci protokolu HTTPS a podpisu XML. Tato alternativa využívá podpis XML k označení všech zpráv odeslaných na server a lze tak ověřit odesílatele zprávy zkontrolováním podpisu. SSL s jednostranným ověřováním (pouze serverový certifikát) se používá k zajištění důvěrnosti a celistvosti zprávy při přenosu a zajišťuje ochranu proti napadení v podobě vymazání nebo opakování a vložení. Namísto vývoje zakázkového softwaru s cílem zavést SSL s oboustranným ověřováním se zavádí podpis XML. Použití podpisu XML se více blíží plánu vývoje internetových služeb než oboustranné zabezpečení SSL, a proto je strategičtější.
Podpis XML lze používat několika způsoby, ale zvoleným přístupem je používat jej jako součást zabezpečení internetových služeb (WSS). WSS určuje způsob, jak podpis XML používat. Jelikož WSS vychází ze standardního protokolu SOAP, je logické tento standard co nejvíce podporovat.
2.3 Bezpečnostní prvky, které se netýkají výměny zpráv
2.3.1
Uživatelé internetové aplikace Eucaris jsou ověřováni na základě uživatelského jména a hesla. Protože se používá standardní ověřování systému Windows, mohou členské státy v případě potřeby zvýšit úroveň ověření prostřednictvím použití klientských certifikátů.
2.3.2
Softwarová aplikace Eucaris podporuje různé uživatelské role. Každá skupina služeb má vlastní povolení. Například (výhradní) uživatelé funkční skupiny „Smlouva o systému Eucaris“ nemohou využívat funkční skupinu „Prümská smlouva“. Služby správce jsou od obvyklých rolí koncového uživatele odděleny.
2.3.3
Softwarová aplikace EUCARIS usnadňuje záznam všech typů zpráv. Funkce správce umožňuje národnímu správci určit, které zprávy jsou zaznamenávány: žádosti od koncových uživatelů, příchozí žádosti od jiných členských států, informace poskytnuté národními registry apod.
Aplikaci lze nastavit tak, aby byla k tomuto zaznamenávání využívána vnitřní nebo vnější (Oracle) databáze. Rozhodnutí o tom, jaké zprávy mají být zaznamenány, zjevně závisí na možnostech zaznamenávání jinde v předřazeném systému a připojených klientských aplikacích.
Záhlaví každé zprávy obsahuje informace o žádajícím členském státu, žádající organizaci v rámci tohoto členského státu a zúčastněném uživateli. Je uveden rovněž důvod žádosti.
Na základě společného zaznamenávání v žádajícím i odpovídajícím členském státě je možné úplné vysledování jakékoliv výměny zpráv (například o žádosti zúčastněného uživatele).
Zaznamenávání nastavuje webový klient Eucarisu (menu Administration, Logging configuration). Funkci zaznamenávání vykonává ústřední systém (Core http). Pokud je zaznamenávání povoleno, celá zpráva (záhlaví a hlavní část) je uložena do jednoho záznamového registru. Pro každou definovanou službu a každý druh zprávy, který prochází ústředním systém, lze nastavit záznamovou úroveň.
Záznamové úrovně
Možnosti záznamových úrovní jsou tyto:
Důvěrná – zpráva je zaznamenána: Záznam NENÍ k dispozici pro službu vypisování záznamů, ale je k dispozici pouze na vnitrostátní úrovni pro potřeby auditu a řešení problémů.
Žádná – zpráva není vůbec zaznamenána.
Druhy zpráv
Výměna informací mezi členskými státy sestává z několika zpráv, jež jsou schematicky znázorněny na níže uvedeném obrázku.
Možnosti druhů zpráv (na obrázku znázorněny jako ústřední systém (Core http) Eucarisu členského státu X jsou tyto:
|
1. |
Request to Core http_Request message by Client |
|
2. |
Request to Other Member State_Request message by Core http of this Member State |
|
3. |
Request to Core http of this Member State_Request message by Core http of other Member State |
|
4. |
Request to Legacy Register_Request message by Core http |
|
5. |
Request to Core http_Request message by Legacy Register |
|
6. |
Response from Core http_Request message by Client |
|
7. |
Response from Other Member State_Request message by Core http of this Member State |
|
8. |
Response from Core http of this Member State_Request message by other Member State |
|
9. |
Response from Legacy Register_Request message by Core http |
|
10. |
Response from Core http_Request message by Legacy Register Na obrázku jsou znázorněny tyto výměny informací:
|
Obrázek: Druhy zpráv pro zaznamenání
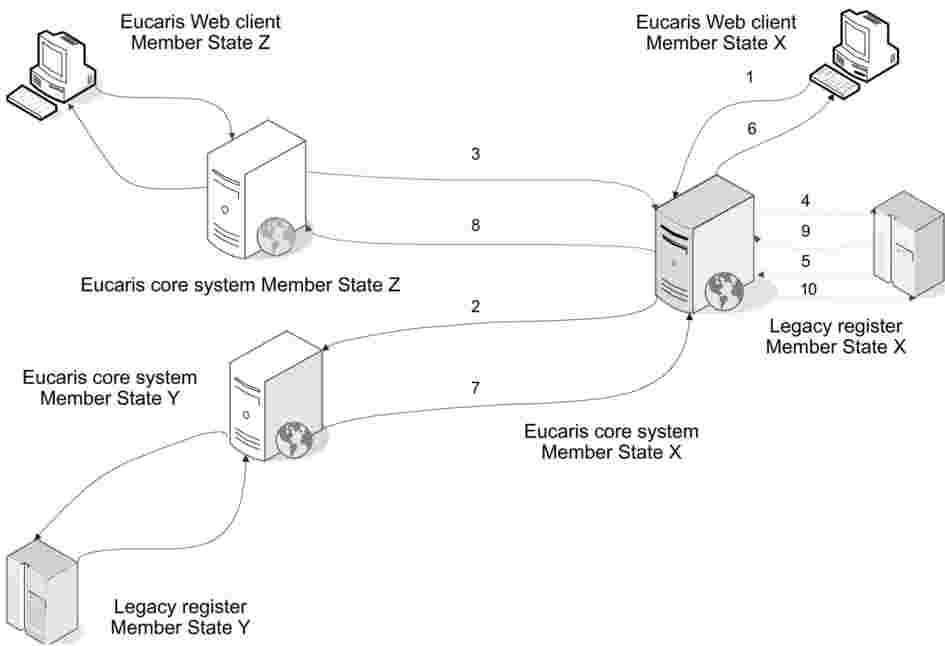
2.3.4
Hardwarový bezpečnostní modul se nepoužívá.
Hardwarový bezpečnostní modul (HSM) zajišťuje vhodnou ochranu pro klíč používaný k označení zpráv a k určení serverů. Doplňuje tak celkovou úroveň zabezpečení, ale pořízení nebo údržba HSM je nákladná a neexistují požadavky na rozhodnutí pro FIPS 140-2 úroveň 2 nebo úroveň 3 HSM. Jelikož se jedná o uzavřenou síť, což účinně omezuje rizika, bylo rozhodnuto HSM zpočátku nepoužívat. Pokud bude HSM nutný, například ke získání akreditace, lze jej do struktury doplnit.
3. Technické podmínky výměny údajů
3.1 Obecný popis aplikace EUCARIS
3.1.1
Aplikace EUCARIS propojuje všechny zúčastněné členské státy do vícecestné sítě, v níž každý členský stát komunikuje přímo s jiným členským státem. K zahájení komunikace není zapotřebí žádného ústředního prvku. Aplikace EUCARIS předává zabezpečené sdělení ostatním členským státům a komunikuje se záložními předřazenými systémy členských států za pomoci XML. Tuto strukturu ukazuje následující obrázek.
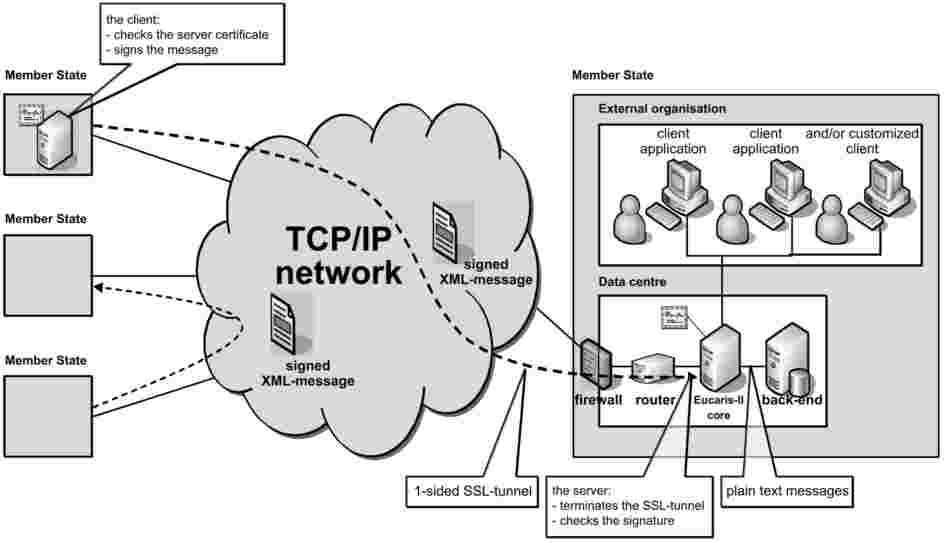
Členské státy si vyměňují zprávy tak, že je přímo zasílají příjemci. Datové centrum členského státu je propojeno se sítí používanou pro výměnu zpráv TESTA. Za účelem přístupu do sítě TESTA se členské státy připojí prostřednictvím brány daného státu. Pro připojení do sítě se použije bezpečnostní brána a směrovač propojí aplikaci Eucaris s bezpečnostní bránou. V závislosti na alternativě zvolené k ochraně zpráv je buď směrovačem, nebo aplikací Eucaris používán certifikát.
Je k dispozici klientská aplikace, kterou lze používat v rámci členského státu pro hledání ve vlastním registru nebo v registrech jiných členských států. Klientská aplikace je propojena s Eucarisem. Klienti budou rozpoznáni na základě uživatelského jména a hesla nebo klientského certifikátu. Spojení s uživatelem ve vnější organizaci (například policie) může být kódováno, za takové kódování je však odpovědný každý členský stát.
3.1.2
Oblast působnosti systému Eucaris je omezena na procesy v rámci výměny informací mezi orgány odpovědnými za registraci v členském státě a na základní předložení těchto informací. Postupy a automatizované procesy, v nichž mají být informace použity, do oblasti působnosti systému nepatří.
Členské státy se mohou rozhodnout použít klientský systém Eucarisu nebo zřídit vlastní klientskou aplikaci upravenou podle jejich potřeb. V níže uvedené tabulce je popsáno, které aspekty systému Eucaris jsou povinné nebo stanovené a které jsou nepovinné nebo o jejichž použití rozhodne členský stát.
|
EUCARIS aspects |
M/O (9) |
Remark |
||||||||||||||||
|
Network concept |
M |
The concept is an „any-to-any“ communication. |
||||||||||||||||
|
Physical network |
M |
TESTA |
||||||||||||||||
|
Core application |
M |
The core application of EUCARIS has to be used to connect to the other Member States. The following functionality is offered by the core:
|
||||||||||||||||
|
Client application |
O |
In addition to the core application the EUCARIS II client application can be used by a Member State. When applicable, the core and client application are modified under auspices of the EUCARIS organisation. |
||||||||||||||||
|
Security concept |
M |
The concept is based on XML-signing by means of client certificates and SSL-encryption by means of service certificates. |
||||||||||||||||
|
Message specifications |
M |
Every Member State has to comply with the message specifications as set by the EUCARIS organisation and this Council Decision. The specifications can only be changed by the EUCARIS organisation in consultation with the Member States. |
||||||||||||||||
|
Operation and Support |
M |
The acceptance of new Member States or a new functionality is under auspices of the EUCARIS organisation. Monitoring and help desk functions are managed centrally by an appointed Member State. |
3.2 Funkční a nefunkční požadavky
3.2.1
V této části jsou obecnými pojmy popsány hlavní obecné funkce.
|
Č. |
Popis |
|
1. |
Systém umožňuje orgánům členských států odpovědným za registraci interaktivní výměnu zpráv s žádostmi a odpověďmi. |
|
2. |
Systém obsahuje klientskou aplikaci, a umožňuje tak koncovým uživatelům zasílat žádosti a předkládat odpovědi k manuálnímu zpracování. |
|
3. |
Systém umožňuje „vysílání“, čímž umožňuje členskému státu poslat žádost do všech ostatních členských států. Přicházející odpovědi jsou hlavní aplikací sloučeny do jedné odpovědi klientské aplikaci (tato funkce se nazývá „průzkum více zemí“). |
|
4. |
Systém je schopen zpracovat různé druhy zpráv. Uživatelské role, povolení, směrování, označení a zaznamenávání jsou všechny definovány podle konkrétní služby. |
|
5. |
Systém umožňuje členským státům výměnu skupin zpráv nebo zpráv obsahujících velký počet žádostí nebo odpovědí. Tyto zprávy jsou zpracovávány asynchronním způsobem. |
|
6. |
Pokud je přijímající členský stát dočasně nedostupný, systém řadí asynchronní zprávy a zaručuje jejich doručení, jakmile bude příjemce opět dostupný. |
|
7. |
Systém ukládá přicházející asynchronní zprávy, dokud nejsou zpracovány. |
|
8. |
Systém umožňuje přístup pouze do aplikací Eucaris jiných členských států, nikoliv jednotlivých organizací těchto členských států, tj. každý orgán odpovědný za registraci funguje jako jediná brána mezi koncovými uživateli svého členského státu a odpovídajícími orgány v ostatních členských státech. |
|
9. |
V rámci jednoho serveru je možné definovat uživatele různých členských států a povolit je na základě práv daného členského státu. |
|
10. |
Zprávy obsahují informace o žádajícím členském státě, organizaci a koncovém uživateli. |
|
11. |
Systém usnadňuje zaznamenávání výměny zpráv mezi různými členskými státy a mezi ústřední aplikací a vnitrostátními registračními systémy. |
|
12. |
Systém umožňuje zvláštnímu tajemníkovi, což je organizace nebo členský stát zvláště určený pro tento úkol, shromažďovat zaznamenané informace o zprávách odeslaných a obdržených všemi zúčastněnými členskými státy, a to za účelem vypracování statistických zpráv. |
|
13. |
Každý členský stát sám určí, které zaznamenané informace poskytne tajemníkovi a které jsou „důvěrné“. |
|
14. |
Systém umožňuje národnímu správci každého členského státu pořizovat statistiku používání. |
|
15. |
Systém umožňuje doplnění nových členských států prostřednictvím jednoduchých správních úkolů. |
3.2.2
|
Č. |
Popis |
|
16. |
Systém poskytuje rozhraní pro automatizované zpracování zpráv prostřednictvím záložních systémů nebo předřazenosti a umožňuje začlenění uživatelského rozhraní do těchto systémů (uživatelské rozhraní podle potřeb klienta). |
|
17. |
Systém se lze snadno naučit ovládat, nevyžaduje vysvětlení a obsahuje nápovědu. |
|
18. |
Systém je opatřen dokumentací, která členským státům pomáhá s jeho začleněním, provozem a budoucí údržbou (například referenční příručka, funkční a technická dokumentace, návod k obsluze…). |
|
19. |
Uživatelské rozhraní je mnohojazyčné a nabízí koncovému uživateli možnosti zvolit jazyk, kterému dává přednost. |
|
20. |
Uživatelské rozhraní umožňuje místnímu správci přeložit položky na monitoru i zakódované informace do národního jazyka. |
3.2.3
|
Č. |
Popis |
|
21. |
Systém je navržen jako výkonný a spolehlivý operační systém, který je odolný vůči chybám operátora a který nepoškodí výpadky elektrického proudu ani jiné pohromy. Musí být možné systém restartovat, aniž by došlo ke ztrátě údajů, nebo pouze s jejich minimální ztrátou. |
|
22. |
Systém musí poskytovat stabilní a reprodukovatelné výsledky. |
|
23. |
Systém byl navržen tak, aby fungoval spolehlivě. Je možné systém zavést v konfiguraci, která zaručuje 98 % dostupnost (zálohováním, použitím záložních serverů apod.) v každé dvoustranné komunikaci. |
|
24. |
Je možné používat část systému i při poruše některých složek (pokud má členský stát C poruchu, členské státy A a B mohou nadále komunikovat). Počet jednotlivých poruch v informačním řetězci by měl být co nejnižší. |
|
25. |
Doba obnovy po závažné poruše by měla být kratší než jeden den. Mělo by být možné minimalizovat prostoj využitím vzdálené podpory, například prostřednictvím centrálního servisního panelu. |
3.2.4
|
Č. |
Popis |
|
26. |
Systém lze používat 24 hodin denně 7 dní v týdnu. Tento časový rámec je tedy rovněž vyžadován od předřazených systémů členských států. |
|
27. |
Systém rychle reaguje na žádosti uživatelů nehledě na úkoly na pozadí. Stejně tak musí předřazené systémy zúčastněných stran zajistit přijatelnou dobu reakce. Přijatelná celková doba reakce pro jednu žádost je maximálně 10 vteřin. |
|
28. |
Systém byl navržen jako systém pro více uživatelů a tak, aby úkoly na pozadí mohly pokračovat současně s úkoly, které uživatel provádí na popředí. |
|
29. |
Systém byl navržen jako přizpůsobitelný objemu, aby vydržel případný nárůst počtu zpráv v případě doplnění nové funkce nebo nových organizací či členských států. |
3.2.5
|
Č. |
Popis |
|
30. |
Systém je vhodný (například svými bezpečnostními opatřeními) pro výměnu zpráv obsahujících důvěrné osobní údaje (například o vlastníkovi/držiteli vozidla) klasifikované jako „EU restricted“. |
|
31. |
Údržba systému je prováděna takovým způsobem, aby nedošlo k neoprávněnému přístupu k údajům. |
|
32. |
Systém obsahuje službu pro řízení práv a povolení vnitrostátních koncových uživatelů. |
|
33. |
Členské státy mohou ověřit totožnost odesílatele (na úrovni členského státu) prostřednictvím podpisu XML. |
|
34. |
Členské státy musí výslovně povolit jinému členskému státu požadovat určité informace. |
|
35. |
Systém zajišťuje na aplikační úrovni přístup úplného zabezpečení a zakódování slučitelný s úrovní zabezpečení vyžadovanou v podobných situacích. Výlučnost a celistvost informací je zaručena použitím podpisu XML a zakódování prostřednictvím tunelu SSL. |
|
36. |
Veškerou výměnu zpráv lze vysledovat pomocí zaznamenávání. |
|
37. |
Je zajištěna ochrana proti napadení v podobě vymazání (kdy třetí strana vymaže zprávu) nebo v podobě opakování či vložení (třetí strana zopakuje nebo vloží zprávu). |
|
38. |
Systém využívá certifikátů důvěryhodné třetí strany. |
|
39. |
Systém může zpracovat různé certifikáty jednotlivých členských států v závislosti na druhu zprávy nebo služby. |
|
40. |
Bezpečnostní opatření na aplikační úrovni jsou dostatečná k tomu, aby umožňovala využití neschválených sítí. |
|
41. |
Systém je schopen používat nové bezpečnostní metody, jako je bezpečnostní brána XML. |
3.2.6
|
Č. |
Popis |
|
42. |
Systém lze rozšířit o nové zprávy a nové funkce. Náklady na úpravy jsou minimální díky centralizovanému vývoji jednotlivých složek aplikace. |
|
43. |
Členské státy mohou definovat nové druhy zpráv pro dvoustranné použití. Všechny členské státy nemusí podporovat všechny druhy zpráv. |
3.2.7
|
Č. |
Popis |
|
44. |
Systém poskytuje nástroje pro monitorování pro centrální servisní panel nebo pro operátory, pokud jde o síť a servery v jednotlivých členských státech. |
|
45. |
Systém poskytuje možnosti pro vzdálenou podporu prostřednictvím centrálního servisního panelu. |
|
46. |
Systém poskytuje možnosti pro analýzu problémů. |
|
47. |
Systém lze rozšířit o nové členské státy. |
|
48. |
Aplikaci může snadno nainstalovat pracovník s minimální kvalifikací a zkušenostmi v oblasti informačních technologií. Instalační proces je pokud možno co nejvíce automatizovaný. |
|
49. |
Systém zajišťuje prostředí stálého testování a schvalování. |
|
50. |
Roční náklady na údržbu a podporu jsou minimalizovány prostřednictvím dodržování tržních norem a prostřednictvím vytvoření aplikace takovým způsobem, aby z centrálního servisního panelu bylo zapotřebí minimální podpory. |
3.2.8
|
Č. |
Popis |
|
51. |
Systém je navržen a opatřen dokumentací tak, aby fungoval řadu let. |
|
52. |
Systém je navržen tak, aby byl nezávislý na poskytovateli sítě. |
|
23. |
Systém odpovídá stávajícímu hardwaru a softwaru v členských státech a vzájemně reaguje s danými registračními systémy pomocí otevřené standardní technologie internetových služeb (XML, XSD, SOAP, WSDL, http, internetové služby, WSS, X.509 atd.). |
3.2.9
|
Č. |
Popis |
|
54. |
Systém vyhovuje prvkům ochrany údajů podle nařízení (ES) č. 45/2001 (články 21, 22 a 23) a směrnice 95/46/ES. |
|
55. |
Systém vyhovuje normám pro výměnu dat mezi správními orgány (IDA). |
|
56. |
Systém podporuje UTF8. |
KAPITOLA 4 Hodnocení
1. Postup hodnocení podle článku 20 (příprava rozhodnutí podle čl. 25 odst. 2 rozhodnutí 2008/615/SVV)
1.1 Dotazník
Příslušná pracovní skupina Rady vypracuje dotazník ke každé automatizované výměně údajů podle kapitoly 2 rozhodnutí 2008/615/SVV.
Pokud se členský stát domnívá, že splňuje podmínky pro sdílení údajů v příslušné kategorii údajů, vyplní příslušný dotazník.
1.2 Zkušební provoz
S cílem vyhodnotit výsledky dotazníku uskuteční členské státy, jež se chtějí zúčastnit sdílení údajů, zkušební provoz společně s jedním nebo více dalšími členskými státy, které již sdílejí údaje podle rozhodnutí Rady. Zkušební provoz se uskuteční krátce před nebo po hodnotící návštěvě.
Podmínky a ujednání ohledně tohoto zkušebního provozu stanoví příslušná pracovní skupina Rady a budou vycházet z předchozí individuální dohody s dotyčným členským státem. O praktických podrobnostech zkušebního provozu rozhodnou členské státy, které se ho účastní.
1.3 Hodnotící návštěva
S cílem vyhodnotit výsledky dotazníku se v členském státě, který se chce účastnit sdílení údajů, uskuteční hodnotící návštěva.
Podmínky a ujednání ohledně této návštěvy stanoví příslušná pracovní skupina Rady a budou vycházet z předchozí individuální dohody mezi dotyčným členským státem a hodnotícím týmem. Dotyčné členské státy umožní hodnotícímu týmu prověřit automatizovanou výměnu údajů v kategorii nebo kategoriích údajů, které mají být hodnoceny, a to zejména tak, že zorganizují program návštěvy, který zohlední požadavky hodnotícího týmu.
Hodnotící tým do jednoho měsíce vypracuje zprávu o hodnotící návštěvě a předloží ji dotyčnému členskému státu k vyjádření. Hodnotící tým tuto zprávu případně dle připomínek dotyčného členského státu upraví.
Hodnotící tým budou tvořit maximálně 3 odborníci určení členským státem, který se účastní automatizované výměny údajů v kategoriích údajů, jež mají být hodnoceny; tito odborníci mají zkušenosti s příslušnou kategorií údajů, absolvovali odpovídající vnitrostátní bezpečnostní prověrku pro tyto záležitosti a jsou připraveni vykonat nejméně jednu hodnotící návštěvu v jiném členském státě. Komise bude přizvána, aby se k hodnotícímu týmu připojila coby pozorovatel.
Členové hodnotícího týmu budou respektovat důvěrnou povahu informací, které při výkonu svého úkolu získají.
1.4 Zpráva pro Radu
Za účelem rozhodnutí podle čl. 25 odst. 2 rozhodnutí 2008/615/SVV bude Radě předložena celková hodnotící zpráva, v níž budou shrnuty výsledky dotazníků, hodnotící návštěva i zkušební provoz.
2. Postup hodnocení podle článku 21
2.1 Statistika a zpráva
Každý členský stát bude sestavovat statistiky o výsledcích automatizované výměny údajů. S cílem zajistit srovnatelnost sestaví příslušná pracovní skupina Rady vzor statistiky.
Tyto statistiky budou každoročně zasílány generálnímu sekretariátu, který vypracuje souhrnný přehled za uplynulý rok, a Komisi.
Kromě toho budou členské státy pravidelně, nejvýše jednou za rok, žádány o poskytnutí dalších informací o provádění automatizované výměny údajů ze správního, technického a finančního hlediska, jichž je zapotřebí k analýze a zlepšení procesu. Na základě těchto informací bude vypracována zpráva pro Radu.
2.2 Revize
Po přiměřené době Rada přezkoumá zde uvedený mechanismus hodnocení a podle potřeby jej upraví.
3.
Odborníci se budou pravidelně scházet v rámci příslušné pracovní skupiny Rady, aby organizovali a provedli výše uvedené postupy hodnocení a aby si rovněž vyměnili zkušenosti a projednali případná zlepšení. Výsledky těchto odborných jednání budou případně začleněny do zprávy podle výše uvedeného bodu 2.1.
(1) „Plně určené“ znamená, že je zahrnuto zpracování vzácných hodnot alel.
(2) Jedná se pozici stanovenou v normě ASCII.
(3) M = povinné, pokud jsou k dispozici v národním rejstříku; O = nepovinné.
(4) Všechny znaky konkrétně přidělené členským státem jsou označeny písmenem Y.
(5) Harmonizovaná zkratka dokumentu, viz směrnice Rady 1999/37/ES ze dne 29. dubna 1999.
(6) M = povinné, pokud jsou k dispozici v národním rejstříku; O = nepovinné.
(7) Harmonizovaná zkratka dokumentu, viz směrnice Rady 1999/37/ES ze dne 29. dubna 1999.
(8) V Lucembursku se používají dva samostatné doklady o registraci vozidla.
(9) M = povinné použití či dodržení; O = nepovinné použití či dodržení.